Table of Contents
업데이트됨
다음은 놀라운 표준 오차 및 채점 문제를 해결하는 데 도움이 되는 가장 사용하기 쉬운 방법입니다.
정의: 추정치의 표준 오차는 계산된 회귀선의 일부에서 진술의 편차와 관련된 이 측정값입니다. 간단하게 회귀선으로 논의되는 예측과 관련된 정확도를 테스트하는 데 사용됩니다.
<제목>
베시 체스넛
Betsy는 일종의 박사 학위를 가지고 있습니다. 모든 멤피스 출신의 대학에서 생물 의학 제품, 버지니아 대학에서 이학 석사, 미시시피 대학 외에서 이학사를 취득했습니다. 그녀는 STEM 프로그램을 개발하고 물리학, 공학 및 생물학을 가르치는 데 10년 이상의 경험을 가지고 있습니다.
캐서린 바디
Katherine은 10시즌이 넘는 기간 동안 고등학교 및 대학교 수학 개념을 가르치고 있습니다. 그녀는 박사 학위를 가지고 있습니다. University of Wisconsin-Milwaukee에서 응용 수학, Florida State University에서 수학 석사, University of Wisconsin-Madison에서 수학 학사 학위를 받았습니다.
표본 평균이 모집단 평균과 동일하다는 것을 정확하게 표시하려는 경우 1/2에 사용되는 일반적인 추정 오류입니다. 표준 오차와 더 일반적으로 관련된 정의, 이를 계산하는 데 사용되는 공식, 예제 및 일반적인 오차가 어떻게 번역되는지 알아보십시오.업데이트: 2021년 12월 23일
버그 감지
고등학교 프로젝트의 일환으로 대학 농구팀의 각 선수가 얼마나 우수한지 측정하기로 결정했다고 가정해 보겠습니다. 팀에 있는 선수들의 평균 키는 72인치입니다. 이것은 여러 농구 선수의 키에 대한 귀하의 야구장 추정치입니까? 어떻게 알 수 있으며 이러한 데이터가 만들어지는 추정치의 가장 중요한 품질을 수량화할 수 있는 방법이 있습니까? 실제로 이것을 정량화하는 데 도움이 되는 방법이 있지만 이러한 질문에 답할 수 있기 전에 먼저 표본과 모집단의 차이점을 이해해야 합니다.
통계에서 패턴 ms는 특정 수집 이력 그룹을 나타냅니다. 이 경우 선택은 대학 직원에 대해 모든 규모의 플레이어와 관련하여 수집한 데이터로 구성될 수 있습니다. 모집단은 표본을 추출한 전체 그룹입니다. 이 소수는 모든 고등학생 농구 선수, 모든 수준의 많은 농구 선수 또는 기타 그룹이어야 할 수 있습니다. 완벽한 모집단을 정의하는 데 도움이 되는 여러 가지 방법이 있으며 항상 우리의 모집단이 얼마인지 명확히 해야 합니다. 이 프로젝트의 경우, 키가 큰 학교의 모든 농구 선수가 키가 크기 때문에 대표팀 농구 선수에 대한 키를 키와 비교하려고 한다고 가정해 보겠습니다. 따라서 인구는 아마도 전적으로 고등학생 농구 선수로 부스트 될 것입니다.
업데이트됨
컴퓨터가 느리게 실행되는 것이 지겹습니까? 실망스러운 오류 메시지에 짜증이 납니까? ASR Pro은 당신을 위한 솔루션입니다! 우리가 권장하는 도구는 시스템 성능을 극적으로 향상시키면서 Windows 문제를 신속하게 진단하고 복구합니다. 그러니 더 이상 기다리지 말고 지금 ASR Pro을 다운로드하세요!

이제 이 하위 집합이 인구를 나타내는 방법을 정확하게 결정하기 위해 모든 고급 무술 학교 농구 선수의 키를 검색하고 측정해야 합니까? 아니, 당연하지! 그 대신, 표본 평균이 실제 모집단 평균에 얼마나 근접한지 잘 알 수 있는 표준 오차를 실제로 계산할 수 있습니다. 큰 표준 오차는 대다수가 현재 모집단에 많은 변동성이 있으므로 다른 표본이 새로운 평균을 제공할 것이라고 상상할 수 있음을 의미합니다. 작은 표준 오차는 인구가 훨씬 더 균질하다는 것을 의미하므로 표본 암시가 확실히 인구에 가깝습니다.
<요소><문자열><리> <리>설문조사
<리>과정
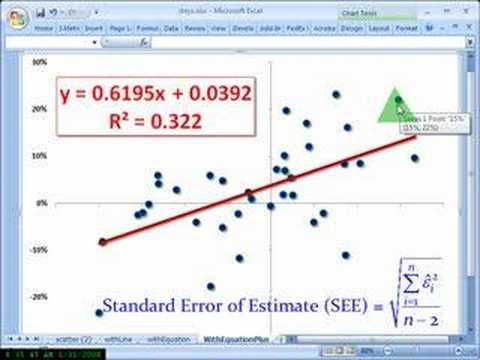
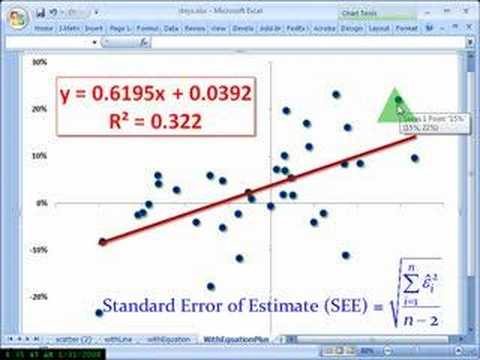
기본 오차를 계산하려면 다음을 수행하십시오. σ가 문자 그대로 표준이고 SE가 표준 오류인 경우 다음과 같은 공식의 형태로 표현된 이러한 단계 중 많은 부분을 분명히 보게 될 것입니다. 일반오차를 찾기 위해서는 많은 단계를 거쳐야 합니다. 고등학교 농구 선수의 경우 이 공식을 수행하는 방법을 이해할 수 있도록 키의 예를 저장합니다. 전문가들이 말하는 것을 상상해 봅시다. 이것은 학교 농구 선수의 키에 대해 수집한 데이터일 뿐입니다. 기준 오차를 확실히 찾는 가장 중요한 단계는 표본 평균을 찾는 것입니다. 이것을 관리하려면 모든 높이에서 더하기 또는 빼기를 더한 다음 일종의 총 측정 수(n은 13)로 나누어야 합니다. 이렇게 하면 연결된 샘플 값이 72로 표시됩니다. 그런 다음 각 과수원에 대한 샘플 의미 및 측정값을 이 모든 값과 비교하여 차이를 계산한 다음 모든 값을 합산합니다. 누구나 화면에서 보는 것과 유사한 테이블을 작성할 수 있으면 관리가 더 쉽습니다. 그런 다음 기본적으로 계산한 합계를 n – 1로 나누고 일반적으로 분산을 얻기 위해 근을 직사각형으로 만드십시오. 표준. 마지막으로 추정치 간의 기본 오차를 계산하려면 큰 표준 차이를 모든 측정값의 제곱근으로 나누십시오(알림: n = 13). . 따라서 표준 오류는 다음과 같습니다. 끝내고 시작하겠습니다. 데이터 세트에 대한 올바른 오류를 찾는 것은 까다로울 수 있습니다. 소유자가 필요로 하는 공식으로 돌아가기 위한 많은 단계가 있습니다. 그러나 현실에서는 모든 것이 쉬워집니다. 읽기 예제에서 학생들은 두 개의 다른 데이터 세트에 대한 기본 오류를 계산하고 해당 데이터 세트에 대한 모든 95% 신뢰 구간을 찾습니다. 모든 학생 예제를 작성하고 나면 가족이 다단계 공식으로 작업하는 동안 표준 오차를 찾는 데 더 집중할 수 있다고 느낄 것입니다. 고등학생 스노보드 선수의 체중 측정에서 고등학교 축구 선수의 평균 잉여 체중 추정치의 기본 오차를 구합니다. 그러면 이 데이터를 찾기 위해 95% 신뢰 구간을 갖게 됩니다. Standard Error And Estimate표준 오차 계산
Σ(xi μ)² – 
표준오차 예
연습 문제
작업 1
Error Estándar Y Estimación
Standaardfout En Schatting
Erreur Type Et Estimation
Błąd Standardowy I Oszacowanie
Standardfel Och Uppskattning
Errore Standard E Stima
Standardfehler Und Schätzung
Erro Padrão E Estimativa
Стандартная ошибка и оценка
년
You Might Also Like