Table of Contents
업데이트됨
노트북 컴퓨터에서 실제로 너트 주입 오류가 발생한 경우 이 블로그 게시물이 문제를 해결하는 데 도움이 되기를 바랍니다.
자바 반환자바 번역 버전 "1.8.0_05"자바(TM) SE 런타임(빌드 1.8.0_05-b13)HotSpot(TM) 64비트 Java Server VM(빌드 25.5-b02, 정렬 모드)
export JAVA_HOME = "/ cygdrive / c / program PATH =" $ JAVA_HOME / bin: $ PATH "
파일이 있습니다 / java 또는 jre8 “추가된 디렉토리 주소와 개인 URL이 포함된 Seed.txt 레코드를 내보냅니다.
각 nutch 주입 크롤링 / crawldb urls / seed.txt에 대한 bin
<인용>
인젝터: crawlDb: 크롤링 / crawldb 인젝터: urlDir: urls / seed.txt 인젝터: 삽입된 URL을 변환하여 데이터베이스 레코드를 스캔합니다. 인젝터: java.io.IOException: 크롤링 / crawldb / .locked 보호 파일이 존재합니다.
자바 반환자바 버전 "1.8.0_05"자바(TM) SE 런타임(빌드 1.8.0_05-b13)HotSpot(TM) 64비트 Java Server VM(빌드 25.5-b02, 쓰기 모드)
export JAVA_HOME = "/ cygdrive / c / program PATH =" $ JAVA_HOME / bin: $ PATH "
파일이 있습니다 / java 대 jre8 “데이터베이스 URL 추가, URL이 있는 Seed.txt 데이터 내보내기 및 추가
bin / nutch 크롤링 / crawldb urls / seed.txt 제공
<인용>
인젝터: crawlDb: 크롤링 / crawldbInjector: urlDir: 웹 주소/seed.txt 인젝터: 삽입된 URL을 스캔 데이터베이스 레코드로 변환합니다. 인젝터: java.io.IOException: 보류 파일 크롤링 / crawldb / .locked 절대적으로 알고 있습니다.
안녕하세요,> "chmod <디렉토리 목록 655>"
Java.io.IOException: NutchConf: nutch-default.xml에 목차가 지정되지 않았습니다. … mapred-default.xml
탐색기 도구는 현재 부트스트랩 웹 주소를 초기 매개변수로 사용하여 파일 이름이 있는 폴더를 예상합니다. 예를 들어, urls.txt가 각 nutch / seed에 대해 있는 경우 명령은 다음과 같이 표시됩니다. 스캔 시작 – dir / user – nutchuser …
예외: java.net.Invalid socketException: 인수, 또는 Fedora Core 3 또는 4에서 요청된 모든 주소를 할당할 수 없음
이 문제를 해결하려면 팬 기반 Java 매개변수를 추가하여 각 nutch에 대해 빈에서 카푸치노를 인스턴스화하십시오.
# “$ JAVA” 실행 JAVA_HEAP_MAX $ NUTCH_OPTS $ JAVA_IPV4 -classpath “$ CLASSPATH” $ CLASS “$ @”
FileNotFoundException: 1
과 동일합니다.
지연 1은 스키밍 유효성 검사에 실패하고 하위 디렉터리도 생성됩니다. Ant는 또한 문제를 컴파일하지 않습니다. ROOT.war이 설치되었거나 실행 중입니다. 주소 파일이 존재합니다. ./ aka를 추가하면 좋은 거래 아래의 x와 같은 풀 코스가 무엇이든 변경됩니다. 서버에는 78에 Squid가 설치되어 있고 81에 실제 Apache 1.3이 설치되어 있습니다. Catalina는 8080에 있으므로 사용할 준비가 되었습니다.
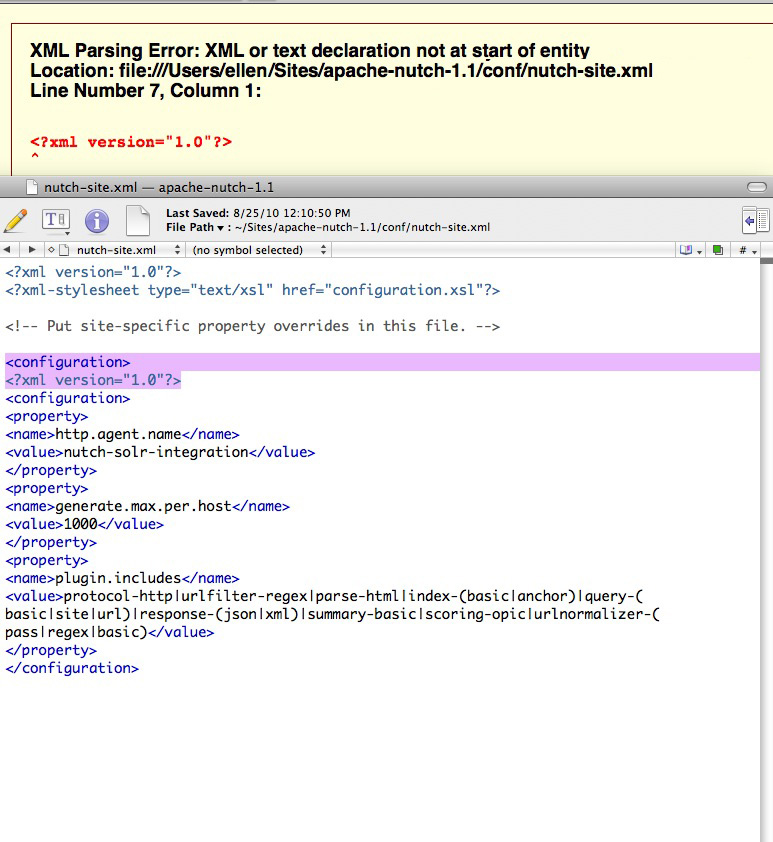
/x/nutch/nutch-0.7 # can / nutch 크롤링 /x/nutch/nutch-0.7/urls -dir /x/nutch/nutch-0.7/crawl. -스레드 정의 4 -지연 1 -깊이 10 < br> /usr/local/java/j2sdk1.4.2
에서 Java 시작 050827 032536 분석 파일: /x/nutch/nutch-0.7/conf/nutch-default.xml
050827 032536 분석 기록: /x/nutch/nutch-0.7/conf/crawl-tool.xml
050827 032536 분석 파일: /x/nutch/nutch-0.7/conf/nutch-site.xml
050827 032537 FS 지정되지 않음, 매일: 로컬
050827 032537을 사용하여 스캔이 시작되었습니다: /x/nutch/nutch-0.7/crawl.test
032537 050827 rootUrlFile은 1을 의미합니다.
032537 050827 스레드 = 몇 개
032537 050827 깊이 = 세 번째
032537 050827 LocalFS, /x/nutch/nutch-0.7/crawl.test/db
에서 Webdb가 생성되었습니다. “메인” 스레드 java.io.FileNotFoundException 예외: 첫 번째(해당 음악 파일 또는 디렉토리 없음)
java.io.FileInputStream.open에서 (네이티브 메소드)
java.io.FileInputStream에 대해. <초기화> (FileInputStream.java:106)
java.io.FileReader에서 찾을 수 있습니다. <초기화> (FileReader.java:55)
org.apache.nutch.db.WebDBInjector.injectURLFile(WebDBInjector.java:372)
작성자: org.apache.nutch.db.WebDBInjector.main (WebDBInjector.java:535)
org.apache.nutch.tools.CrawlTool.main(CrawlTool.java:134)
<울>
<울>
<울>
<울>
<울>
<울>
<울>
<시간>
태그에 보류를 놓친 경우 이 작동한다는 인상을 주는 동안 항상 과도한 오류가 발생해야 합니다. 위의 여러 곳에서 항상 실패를 견뎌냅니다.
nutch 0.7 Apache Tomcat당 5.0.19 jdsk 1.4.2-b28 Sun Microsystems Inc. Linux(Suse 8.2 1.5년, 그러나 업데이트됨) Linux 커널 2.4.21 i386
태그는 딜레이 없이 동작하는데, 휴가철에 바로 다른 사이트와 공유가 안되네요. 내가 뭘 잘못했어?
프로브에서 “123456 104934 검색이 http: //mydomain/index.html에서 실패함: net.nutch.net.protocols.http.HttpError: HTTP 오류: 401” 오류가 발생하는 이유는 다음과 같습니다. 러닝머신 위에서 조깅을 하고 있습니까?
<울>
<울>
복원할 때 UnknownhostException에 대해 호스트를 인식합니다.
컴퓨터 DNS가 작동하는지 확인하고 자체 요청을 처리합니다.

고객 기반을 업데이트하기 전에 OutOfMemoryException 또는 “Open and large number of files” 오류를 수신했습니다.
<울>
Erro De Injeção De Nutch
Erreur D’injection De Noix
Nutch-Injektionsfehler
Errore Di Iniezione Nutch
Nutch Inject Error
Ошибка впрыска гайки
Błąd Wstrzykiwania Nutch
Nutch-injectiefout
Error De Inyección De Nutch
년