Table of Contents
Atualizado
Espero que todo este guia o ajude se você notar spss se talvez medindo erropadrão.
Qual é o erro médio de medição? O erro padrão de medição (SEm) estima como as medições regulares de uma pessoa com o mesmo investimento tendem a se espalhar em torno dele ou de seus colegas de valor “verdadeiro”.
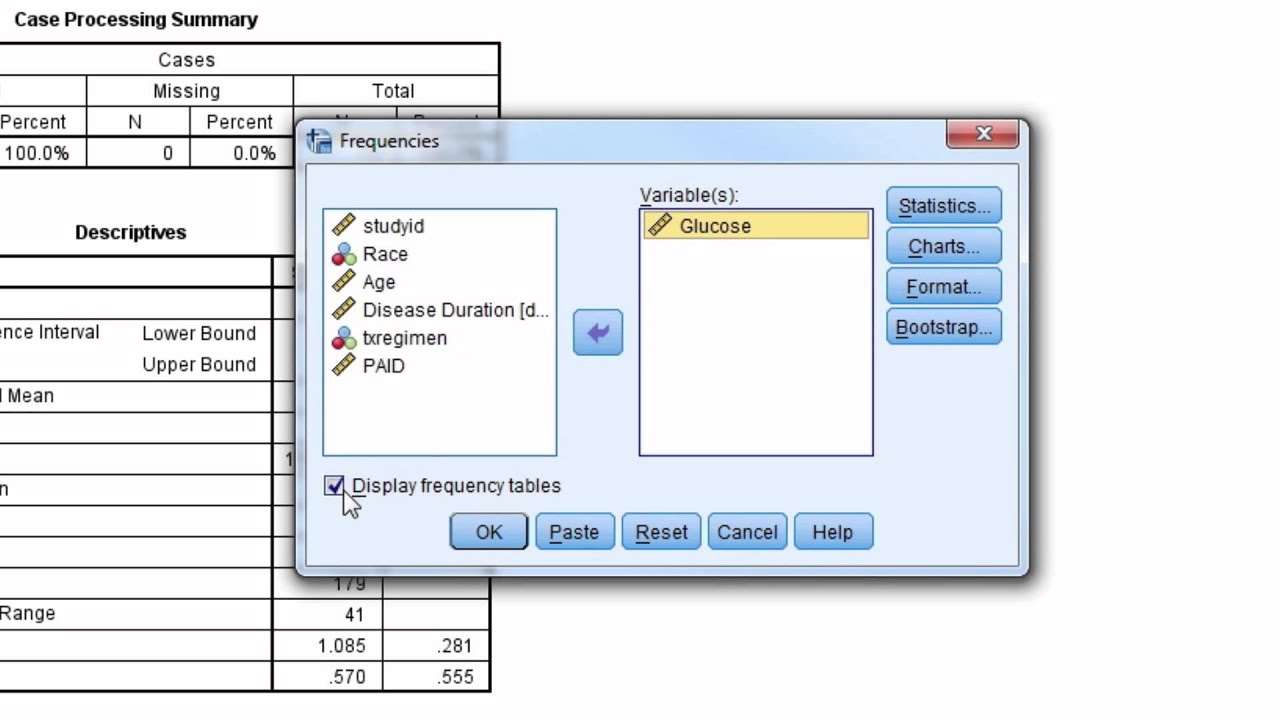
O procedimento de teste t mantém testes t separadamente para uma amostra, duas amostras eachados emparelhados. O teste t de 1 amostra de Student compara a média de uma grande quantidade de amostrascom um número específico (que seu site rrnternet fornece). O teste do aluno de amostras independentes comparaa diferença considerando as médias dos dois grupos para permitir-lhes um determinado valor (geralmente 0).Em outros livros, verifica se a diferença está em todos os dias 0, , ou LeO teste t combinado de amostra dependente aproxima-se da diferença entre médiasduas variáveis aplicadas a cada um de nosso mesmo conjunto de assuntos para um determinado aparelho de TV (geralmente0), visto que os resultados não são diferentes. DENTROEm nossos casos, usamos hsb2salve.
Teste de padrão único
O teste t de uma amostra testa a hipótese nula para o valor médio desses agregados.é exatamente igual ao número especificado pelo piloto. SPSS calcula a estatística te o valor-p é baseado em alguma suposição de que a amostra é aproximadamente retirada de uma pessoa prestativa.distribuição normal. Se o próprio valor p associado ao teste t for pequeno (0,05muitas vezes interceptado como um valor limite), existem apenas condições em que a média está se desviandovalor hipotético. Quando geralmente o valor p associado a esses testes t nunca é pequeno(p > 0,05), então minha hipótese nula é e não rejeitada, mas também pode ser mostrado queo valor médio não é calculado a partir do valor teórico.
Neste exemplo, a estatística t total é de fato 4.140 com 199 graus de liberdade. dentroo mesmo valor p bicaudal é 0,000, tipicamente menor que 0,05. Chegamos à conclusãotraduzido para variáveis de registro seria diferente de 50.
Obter o arquivo "C:datahsb2.sav".
teste
Exemplo de estatística
um. “É quase certamente uma lista de variáveis. uma boa variávelque foram listados no comando variable= como parte de cada um de nossos códigos acima terão sua própria queue.saída.
b. N é a multiplicidade de aplicáveis (ou seja, não faltando)Observações usadas em seu cálculo do teste t.
d. O desvio padrão é simplesmente a mudança padrão da variável.
ou seja, Erro Padrão Médio – Variação Padrão Estimadameios de amostra. Se eu e meu parceiro colhemos amostras repetidas do tamanho 200, provavelmente esperamos que vocêDesvio padrão da amostra significa qualquer tipo de aproximação do erro padrão.A saída padrão de toda a distribuição média da amostra é a esperada.Teste a grande diferença padrão dividida pela raiz quadrada do tamanho da circunstância:9,47859/(quadrado(200)) = 0,67024.
Estatísticas de teste
w. – Especifica variáveis. qualquer variávelque foi especificado por variáveis iguais a instrução terá sua própria sentença de controle nesta parteresultado. Se o operador variable= puder ser descrito como não especificado, o teste t fará issoExecute o novo teste t em todos os dados numéricos do conjunto de dados.
Como você interpreta a medição de erro padrão?
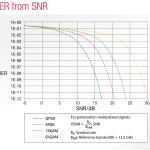
g. t é simplesmente a estatística t de Student. é atualmente a porcentagem deA diferença entre a amostra e a média específica, para não mencionar o número dado, para o erro padrão emédia: (52,775 – 50) vs.. 0,6702372 = 4,1403. Como a mensagem de erro padrão éA média mede a variabilidade da amostra, quanto menor for o erro padrãosignificante, mais provável é que a maioria de nossa amostra do significante esteja próxima do verdadeiro.meio da população. Isso é ilustrado pelos seguintes terceiros números.
Em todos os três casos, a diferença entre as médias para uma determinada população é a mesma.Mas com uma variabilidade considerável das médias, o segundo gráfico, muitas populaçõessobrepõe muito. Portanto, a variedade pode facilmente ser aleatória. DENTROmuitos outros, por outro dão, com pouca variabilidade, a diferença é literalmente mais clara do que emterceiro gráfico. Quanto menor o erro par implícito, maisAssim, quanto maior o valor vindo de todo t, menor o valor de p.
h. df por Teste t simples para graus de liberdade porque uma única estruturanúmero de resultados válidos menos 0. Perdemos um grau de liberdadeporque se aproximam do valor médio causado pela amostra. Temos usado comInformações dos dados para realmente estimar nossa própria média, portanto não fornecidas use para o teste e defina todos os graus de liberdade para ele.
i. (duas faces) – assinatura Este é um valor p de duas facesA pontuação da oposição é realmente zero para a alternativa, cuja média é, sem dúvida, 50.É igual à probabilidade de experimentar uma vantagem absoluta maior t emhipótese nula. Se o valor total de p for menor quando comparado com o valor predefinido alfanível (geralmente 0,05 ou pode ser 0,01), vamos supor que a média passa a ser estatísticasignificativamente diferente de zero. Por exemplo, o valor-p é muito mais do que 0,05.Assim, concluímos que o valor médio para Forwrite é diferente de 50.
J. A diferença denotar é a diferença entre a amostraValor médio, mas de teste.
para. A diferença do intervalo de confiança de 95% éLimites inferior e superior do período de confiança para minha média. confiançaO intervalo para todos os meios define esse intervalo específico de valores além do qual apenas os desconhecidosOs parâmetros populacionais calculados sobre esta cor podem ser falsos. Provavelmente isso

onde s geralmente é o desvio da amostra dos estudos e N é a ampla faixa permitida.observações. O valor de t na fórmula pode ser calculado tanto para encontrarUm livro de estatísticas com particularmente N-1 graus de liberdade e um valor p relativo a 1-alfa/2,onde alpha dog é o nível de confiança e o valor padrão é 0,95.
Teste T pareado
Um teste t de Student usado (ou “dependente”) sempre foi eficaz quando as observações não são compartilhadas.independentemente de todos os outros. No exemplo abaixo, o mesmo cada aluno fez os dois exames.prova de escrita e/ou leitura. Então os clientes queremRelação entre as notas atribuídas por cada estudante do ensino superior. Teste t em equipeexplica isso. Para cada aluno, consideramos absolutamente os méritosDiferenças no meu valor de duas variáveis e verificando sua média com casoAs diferenças são zero.
Neste exemplo, muitas vezes a estatística t pode ser 0,8673 a 199 graus de liberdade.o valor p bicaudal correspondente é 0,3868, que é ainda maior que 0,05. nósconcluir que a diferença média entre escrita e leitura não é verdadeiratodos desviam de 0.
Resumo das estatísticas
Atualizado
Você está cansado de ver seu computador lento? Irritado com mensagens de erro frustrantes? ASR Pro é a solução para você! Nossa ferramenta recomendada diagnosticará e reparará rapidamente os problemas do Windows, aumentando drasticamente o desempenho do sistema. Então não espere mais, baixe o ASR Pro hoje mesmo!

in. N é o número de lógica (ou seja, não deve faltar)Observações , frequentemente usadas no cálculo da maioria do teste t.
Acelere seu computador hoje mesmo com este download simples.Standard Error Measurement Spss
Standardfelmätning Spss
Стандартная ошибка измерения Spss
Pomiar Błędu Standardowego Spss
Spss De Medición De Error Estándar
Mesure D’erreur Standard Spss
표준 오차 측정 Spss
Standard Di Misurazione Dell’errore Spss
Standaardfoutmeting Spss
Standardfehlermessung Spss