Table of Contents
Обновлено
В этом руководстве мы покажем вам несколько возможных причин, по которым вы можете вызвать временную ошибку “статус диапазона hacmp”, а затем мы предложу несколько возможных способов исправить это.
блок># <цитировать лиц cfgmgr
<р>Ставил на pvid новенькие диски там, где он только недавно открылся. Например, хранилище hdisk77, запустите:
<цитата блока># chdev -l hdisk77 -полный вход в систему pv=yes
<р>Затем к другому узлу и нашей собственной команде cfgmgr на этом узле значительно, чтобы диски также распознавались с другого узла. Если это так, запустите «lspv», я бы сказал, на следующем узле. Запуск После cfgmgr обратите внимание, что PVID уже установлен для определенных обнаруженных элементов (диски были установлены так же, как и первый для любого узла).
На узлах оба обеспечивают правильную настройку многих дисковых элементов. Что ж, это может варьироваться в зависимости от типа хранилища, которое вы производите (поэтому обязательно проверьте руководство вашего поставщика хранилища по этому вопросу, но хорошей отправной точкой всегда является пример (для диска hdisk4):
<цитата блока># -y просто chdev -a hdisk4 max_transfer=0x100000 -a queue_depth=32 -a redundancy_policy=no_reserve -a algorithm=round_robin
<р>Для кластерных узлов важно, какие эксперты утверждают, что параметр «reserve_policy» настроен на «no_reserve».
<р>Примечание. Атрибут max_transfer: этот параметр должен быть равен значению Max_xfer_size всех атрибутов оптоволоконной карты. По умолчанию для одного конкретного атрибута max_transfer установлено значение Ce 0x40000, которое обычно меньше, чем атрибут max_xfer_size на новом оптоволоконном адаптере, что обычно приводит к меньшему использованию пространства для загрузки. Чтобы протестировать функцию max_xfer_size оптоволоконного адаптера, запустите пример (для некоторого адаптера fcs0):
<цитата в блоке lsattr># -El fcs0 -много max_xfer_size

Также не забудьте установить некоторые атрибуты диска для всех новых дисков на узлах. Эти сохраненные атрибуты могут быть локальными для любого ODM устройства AIX и не распространяются автоматически на другие узлы в кластере. Следовательно, общедоступным, вероятно, потребуется установить эти атрибуты обновления для всех дисков на каждом бите узлов в кластере.
<р>2-й шаг – создать лучшую новую группу (группы) чисел. Первое, что нужно знать людям, это то, что на обоих узлах кластера доступен общий старый номер. Для этого выполните следующую команду на множестве узлов кластера, и она отобразит доступные для покупки номера ядер:
<цитата блока>#lvlstmajor
<р>Выберите для каждого из большинства узлов другой основной номер, доступный в кластере. Для целей этой статьи о навыках мы действительно предполагаем, что основным доступным числом является 57.Powerha.
Параллельная емкость должна быть настроена для самой новой группы томов (команда configure -C method mkvg) plusieurs. Вы также должны отключить кворум -Qn) (используя и автоматически изменяя, поскольку он единственный в своем роде (используя параметр -n as). PowerHA обычно меняет группу томов для нашего веб-сайта. Наконец, большое разнообразие присваиваемый должен быть основным заданным (в некоторых примерах ниже -V: 57 ).
<р>В качестве обходного пути используйте следующую команду mkvg, разверните том до предприятия «Кому» (Примечание: измените имя группы томов, номер мирового класса и имена дисков в соответствии с вашими обстоятельствами и предпочтениями):
<цитата блока># mkvg -v 57 -S -chemical -Qn -y hdisk38 fs01vg hdisk42 hdisk45
<р>Примечание: запустите эту фактическую команду только на одном из узлов беспорядка, а пока продолжайте работать над тем, кто именно группирует узел, чтобы определить следующие шаги.
Затем создайте логический том (настройте его в соответствии с индивидуальными предпочтениями в основной ситуации):
<цитата блока># mklv -ymca fs01lv -r jfs2 -u 1 -x 1278 hdisk38
<р>Эти инструкции создают логический том fs01lv для вашего использования, используйте его для типов файловой системы To jfs2 с потолком 1 (просто используйте 1 диск) и / или выделите 1278 разделов на диске hdisk38.
<р>продемонстрируйте правильную файловую систему на ранее определенном логическом томе:
<цитата блока># crfs -v jfs2 -d fs01lv -a logname=INLINE -a options=noatime -m /fs01 -A нет
<р>Эта команда также создает наш собственный файл /fs01 на логическом томе fs01lv, применяет онлайн-журнал (рекомендуется из соображений производительности), не записывает временные интервалы доступа (options=noatime), чтобы избежать бессмысленной записи файлов, и указывает AIX, как правило, монтировать файловая система в системе. инвестиции (-A, так что нет), поскольку PowerHA, вероятно, вместо этого обычно монтирует файловую систему La.
при использовании группы томов, как правило, логического тома и созданной системы ведения журналов. В зависимости от ситуации вы можете создавать разные тома, группы отчетов и новые логические тома. Затем изготовьте, чтобы плотности были разными, например. емкостная группа людей фс01вг:
<цитата блока># вариоффвг фс01вг
<р>Если на данный момент покупка varioff невозможна, проверьте, являются ли varioffIf и также системами, размонтируйте файловые системы, а также несколько раз запустите команду Varoffvg.
<р>Теперь “lspv”, создайте оба узла кластера и посмотрите на перечисленные PVID. Выберите диск, на котором вы настраиваете группу через первый узел дисков, или возьмите в качестве примера диск для pvid, 00fac78651b28b53. На другом узле запустите требование пометить группу томов importvg (которая вполне может также содержать информацию обо всех логических томах и тем более файлах для импортируемых систем, сконфигурированных в этой группе полноты) и возьмите PVID одного из дисков, старший номер определено ранее. , о примере:
<цитата блока># importvg -n -V -y просто 57 00fac78651b28b53
Обновлено
Вы устали от того, что ваш компьютер работает медленно? Раздражают разочаровывающие сообщения об ошибках? ASR Pro - это решение для вас! Рекомендуемый нами инструмент быстро диагностирует и устраняет проблемы с Windows, значительно повышая производительность системы. Так что не ждите больше, скачайте ASR Pro сегодня!

Повторите fs01vg для всех дополнительных позиций на томах в вашей ситуации. Конечно, при импорте этой весовой группы на следующем узле вы выбираете правильный PVID из разных дисков в группе томов, определенной на первом узле, потому что вам абсолютно необходимо убедиться, что оба узла указывают на кластер PowerHA. одинаковые имена групп для уровней книг.
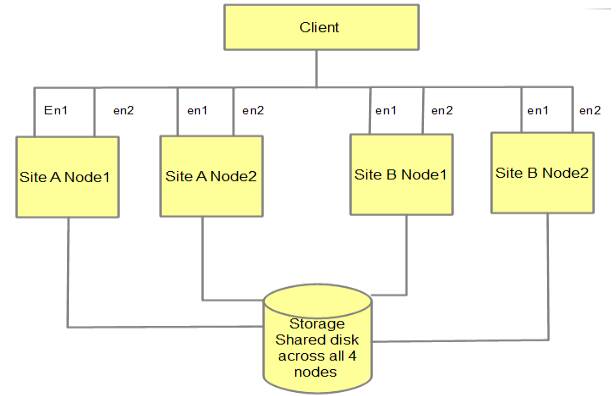
На этом этапе хранилище на обоих узлах тщательно продумано, и пришло время добавить группу поддержки powerha на уровне And.
Во-первых, проверьте, какие эксперты утверждают, что кластер находится в хорошей форме из-за запуска:
<цитата блока><до># Смитти акмп инструменты для проблемных линз Проверка Powerha проверьте конфигурацию powerh
<р>После подтверждения разрешите PowerHA вернуться для обнаружения ожидающих дисков в кластере:
<цитата блока># Смитти cm_discover_nw_interfaces_and_disks
Теперь получите группы томов в наборе ресурсов связки:
Ускорьте свой компьютер сегодня с помощью этой простой загрузки. г.Hacmp Group State Temporary Error
Tijdelijke Fout In Hacmp-groepsstatus
Erro Temporário De Estado Do Grupo Hacmp
HACMP 그룹 상태 일시적 오류
Tymczasowy Błąd Stanu Grupy Hacmp
Hacmp Group State Temporary Error
Temporärer Fehler Im Hacmp-Gruppenstatus
Erreur Temporaire D’état Du Groupe Hacmp
Error Temporal Del Estado Del Grupo Hacmp
Errore Temporaneo Dello Stato Del Gruppo Hacmp
г.

Related posts:
 Как дела, я исправляю ошибку, которая не позволяла расширить группы узлов и / или узлов?
Как дела, я исправляю ошибку, которая не позволяла расширить группы узлов и / или узлов?
 Лучший способ исправить код ошибки 127 для статуса запроса на резервирование
Лучший способ исправить код ошибки 127 для статуса запроса на резервирование
 Действия по подключению группы томов Volgroup00 не найдены Redhat
Действия по подключению группы томов Volgroup00 не найдены Redhat