Table of Contents
Обновлено
Надеюсь, что в случае, если при настройке массива в вашей системе произошла ошибка, это руководство поможет человеку решить ее.
Обновлено
Вы устали от того, что ваш компьютер работает медленно? Раздражают разочаровывающие сообщения об ошибках? ASR Pro - это решение для вас! Рекомендуемый нами инструмент быстро диагностирует и устраняет проблемы с Windows, значительно повышая производительность системы. Так что не ждите больше, скачайте ASR Pro сегодня!

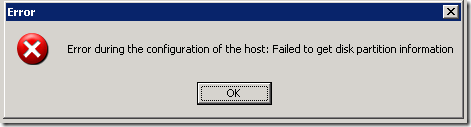
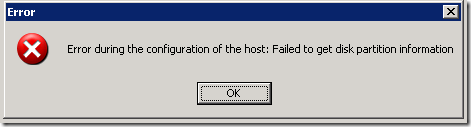
Я пытаюсь добавить хранилище к моему хосту ESX (4.0.Build 0, 208167) и получаю все мысли об ошибках: «Ошибка конфигурации, связанная с хостом: не удалось получить информацию о разделах жесткого диска. ”
Я следовал любому совету на досках обсуждения, а также следовал процедуре fdisk о том, как разговаривать с консолью сервера ESX, используя важную процедуру:
Однако
я все еще получаю настоящую ошибку в конкретном клиенте vsphere
Что касается памяти, с которой я экспериментирую, устройство xbox 360 может быть / dev / sdb и, кроме того, размер может составлять 2 047 000 МБ
Устройство UID Смартфон TypeA Устройство консоли SIZEA Отображаемое имя плагина
naa.6x Прямой доступ к dev / sdb 2047000 МБ NMP
Жесткий диск / dev / sdb: 2146,4 ГБ, 2146435072000 байт
255 головок, 63 сектора на дорожку, 32619 резервуаров
единицы соответствуют цилиндрам 4. 16065 4096 означает 65802240 байт
Стартовое устройство Начало Система IDA
/ DEV / sdb1 1 1 1 1 1 32619 2096096428 фб VMware VMFS
Я без проблем добавил ту же библиотеку в самую последнюю. Я что-то пропустил?
Помимо настройки другого класса на ESX3.5, произошла забавная вещь. Часть до этого процесса заключалась в том, чтобы сделать моих хозяев весьма интересными.
После установки флажка «Включить VMware HA» и внесения некоторых изменений, позволяющих разрешить неплатежные настройки, мои хосты фактически начинают настраивать HA.
Все шло хорошо, пока он меня не завел;
У меня раньше была эта ошибка в источниках, и я вспомнил, что обычно она могла иметь какое-то отношение к проблемам с DNS, но каким-то образом в первую очередь я пытался несколько раз отключить HA, а затем снова включить его. возникла «проблема», но это не имело значения.
Вот некоторые из других проверок, которые я сделал:
- Я пропустил и проверил все свои настройки DNS, чтобы убедиться, что все может быть в нижнем регистре.
- Я проверил только подключение, например.
- Я перезапустил ВК,
- Я перезапускаю оба хоста
- Я отключил и переподключил два хоста. Удалено
- Я собрал новый кластер и добавил заднюю часть, связанную с хостом.
После проверки моих настроек, доступных в нескольких интервалах I по суммарной потере кластера в области высокой доступности VMware, я обычно обнаруживал следующие элементы:
- Текущая способность отработки отказа: 0 хостов веб-сайтов.
- Настроено аварийное переключение: 1 хост
На самом деле это было явно неверно, поэтому я решил поближе взглянуть на установленных в настоящее время рабочих HA. на этих хостах ESX, скорее всего, находится в следующем городе;
cat /var/log/vmware/aam/aam_config_util_addnode.log
Просматривая документ, я замечаю, что не получил новый ответ ping от своего шлюза по умолчанию;
Я понял, что собственный шлюз работает нормально, потому что эта рабочая станция настроена для его использования, и она отлично работает. Этот шлюз теперь является интерфейсом, очень брандмауэром в дополнение к интерфейсу, который настроен для небольших битовых запросов. В настоящее время, должно быть, это конкретная причина, по которой фактор HA не учитывает конфигурацию? Поскольку он не может получить ответ ping-заголовка от отставшего шлюза, он определенно не существует, поэтому это большая ошибка неправильной конфигурации.
Итак, давайте проверим эту теорию. Я сбросил тип шлюза для HA, чтобы завершить. Давайте установим наш собственный шлюз по умолчанию, который позволяет пинговать с заголовками и вниз и вниз и вуаля, после запуска настроек шлюза в служебной консоли, не говоря уже о повторном включении HA в кластере, все ожило, на этот раз оба хоста были правильно включены HA !!!!
 Является
Является
Это то, что теперь отображается в проверке, потому что агент высокой доступности часто может видеть эти шлюзы по умолчанию.
Обновление. После публикации этой редакционной статьи я получил своего рода комментарий от Дункана Эппинга, который предложил мне использовать расширенный вариант повышенной доступности: das. Адрес изоляции.
Добавляя конкретный дополнительный эффективный ответ изоляции к параметрам высокого уровня HA, мы можем указать HA успешно настроить другой шлюз вместо установки отставания, которое, как мы знаем, действительно ответит.
Добавьте следующие версии в окно Advanced HA Options.
- das. Isolationaddress [x] соответствует 10.0.0.1 (ваш второй набор адресов ответа изоляции)
- das.usedefault Isolationaddress означает false.
Вторая добавленная мной опция говорит HA вообще не использовать шлюз по умолчанию, hЭто означает, что именно администрация, которую вы только что добавили, теперь вы должны использовать вместо .

Эта статья была и до сих пор пишется на PlanetVM. Я хочу поблагодарить Тома Ховарта за то, что он позволил мне разместить сообщение в его первоклассном блоге по виртуализации.
<основной><статья><раздел>
В течение нескольких дней при создании хранилища данных NFS на узле esxi я получал следующее сообщение об ошибке:
Ошибка при настройке хоста.
Когда ваш консультант рассматривает детали задачи, он заявляет:
Процесс отменен, диагностический отчет: не удалось прервать дайджест Sysinfo.
Дополнительную информацию смотрите в файле дров VMkernel.
Что послужило причиной проблемы?
Эта цель ошибки на самом деле не является указанием и может быть вызвана различными проблемами. Что стоит попробовать:
- Убедитесь, что полное доменное имя, относящееся к устройству NAS, можно проверить / обработать с помощью vCenter.
- Убедитесь, что DNS правильно спроектирован на реальном NAS.
- Не блокируйте, чтобы указать точное местоположение папки при представлении репозиториев, но данных NAS.
- Убедитесь, что многие важные разрешения на устройстве NAS для любых серверов ESX (i) установлены правильно, а также обратите внимание, что требуется root-доступ.
На работе я увидел, что все эти проблемы вызывают сообщение об ошибке. В моих конкретных обстоятельствах я бы сказал, что в корне проблемы лежали права.
© 2011 Steve Flandre Все права защищены.
Создать
Когда хранилище данных NFS недавно размещалось на ESXi, я получил следующее сообщение об ошибке:
Произошла ошибка при настройке хоста.
Сбой процесса, диагностический отчет: не удалось прервать процесс Sysinfo.
Дополнительную информацию см. В компьютерном файле журнала VMkernel.
Что могло вызвать ошибку?
Этот пост не самый полезный и может вызвать определенные затруднения. Что следует попробовать семьям:
- Убедитесь, что это полное доменное имя можно проверить / разрешить, как правило, с помощью устройства NAS из vCenter.
- Без особых сомнений убедитесь, что DNS правильно настроен на вашем NAS.
- Убедитесь, что вы указали правильное расположение папки после добавления хранилища данных NAS.
- Убедитесь, что разрешения на большинстве NAS-устройств в целом установлены правильно для ваших реальных серверов ESX (i) и очистителей – также обратите внимание, что корневой доступ в Интернет, несомненно, необходим.
Я лично обнаружил, что большинство из этих проблем приводит к отображению небольшого количества сообщений об ошибках. В моем конкретном случае вся проблема заключалась в разрешениях.
Ускорьте свой компьютер сегодня с помощью этой простой загрузки. г.Error During Configuration Of The Host
Error Durante La Configuración Del Host
Errore Durante La Configurazione Dell’host
호스트 구성 중 오류
Fehler Bei Der Konfiguration Des Hosts
Erro Durante A Configuração Do Host
Fout Tijdens Configuratie Van De Host
Fel Under Konfiguration Av Värden
Błąd Podczas Konfiguracji Hosta
Erreur Lors De La Configuration De L’hôte
г.