Table of Contents
Zaktualizowano
Mam nadzieję, że jeśli podczas konfigurowania hosta w dobrym systemie wystąpił błąd, ten przewodnik pomoże Ci w tym.
Zaktualizowano
Czy masz dość powolnego działania komputera? Denerwują Cię frustrujące komunikaty o błędach? ASR Pro to rozwiązanie dla Ciebie! Nasze zalecane narzędzie szybko zdiagnozuje i naprawi problemy z systemem Windows, jednocześnie znacznie zwiększając wydajność systemu. Więc nie czekaj dłużej, pobierz ASR Pro już dziś!

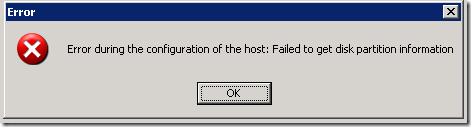
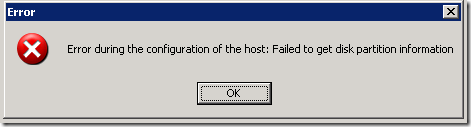
Próbuję przydzielić pamięć do mojego hostingu ESX (4.0.Build 0, 208167) i dodatkowo otrzymuję wszystkie komunikaty o błędach: „Błąd konfiguracji podłączony do hosta: nie udało się uzyskać twardego dysku informacje o partycji dysku.”
Postępowałem zgodnie z niektórymi z rad na forach dyskusyjnych i postępowałem zgodnie z tą procedurą fdisk, jak połączyć się z całą konsolą serwera ESX przy użyciu następującej procedury:
Jednak
nadal otrzymuję ten sam błąd w konkretnym kliencie vsphere
Jeśli chodzi o pamięć, z którą eksperymentuję, konsolą może być / dev / sdb, a długość i szerokość mogą mieć 2 047 000 MB
Urządzenie UID Urządzenie TypeA Konsola SIZEA Wyświetlana nazwa wtyczki
naa.6x
Dysk twardy lub dev / sdb: 2146,4 GB, 2146435072000 bajtów
254 głowice, 63 sektory / ścieżka, 32619 zbiorników
jednostki odpowiadają cylindrom * 16065 4096 oznacza 65802240 bajtów
Urządzenie startowe Start IDA System
/ DEV na sdb1 1 1 1 1 1 32619 2096096428 fb VMware VMFS
W przeszłości przyczyniłem się do tej samej biblioteki, która nie dotyczyła Twojego problemu życiowego. Przegapiłem coś?
Podczas zakładania nowej klasy W ESX3.5 wydarzyła się jedna śmieszna rzecz. Częścią tego procesu byłoby zapewnienie wysokiej dostępności moich hostów.
Po zaznaczeniu pola wyboru Włącz VMware HA i wprowadzeniu pewnych zmian w celu umożliwienia ustawień domyślnych, moje hosty faktycznie zaczynają konfigurować HA.
Wszystko szło dobrze, dopóki nie przedstawiono mu tego, co by mnie pomogło;
Miałem wcześniej ten błąd ze źródłami i pamiętałem, że zwykle może to mieć związek z problemami z DNS, ale najpierw próbowałem wyłączyć HA kilka okresów, a następnie ponownie go włączyć. był szczególny „problem”, ale to nie miało znaczenia.
Oto niektóre z innych przeprowadzonych przeze mnie kontroli:
- Brakowało mnie i sprawdziłem wszystkie moje ustawienia DNS, aby upewnić się, że wszystko jest małe.
- Sprawdziłem wszystkie połączenia, np.
- Uruchomiłem ponownie VC,
- Ponownie uruchamiam 2 główne hosty
- Rozłączyłem się i ponownie połączyłem z hostami. Usunięto
- Odbudowałem najnowocześniejszy klaster i dodałem tył koordynatora.
Po sprawdzeniu moich ustawień w wielu odstępach czasu na karcie podsumowania klastra w ich obszarze VMware HA, zwykle znalazłem następujące słońce i wiatr:
- Aktualna pojemność przełączania awaryjnego: 0 hostów
- Skonfigurowano przełączanie awaryjne: 1 host
To było wyraźnie niepoprawne, więc postanowiłem przyjrzeć się aktualnie zainstalowanym agentom HA. na większości z tych hostów ESX może znajdować się w następującej lokalizacji;
kot /var/log/vmware/aam/aam_config_util_addnode.log
Przeglądając dokument, zauważam, że nigdy nie otrzymałem nowej odpowiedzi ping z mojej domyślnej bramy;
Zdałem sobie sprawę, że moja brama faktycznie działa dobrze, ponieważ ta stacja robocza została zaprojektowana do jej używania, działa dobrze. Ta brama jest teraz interfejsem, zaporą sieciową, która wykorzystuje dodatek do interfejsu, który został złożony dla małych żądań bitowych. Czy obecnie był to nowy konkretny powód, dla którego agent HA niekoniecznie brał pod uwagę konfigurację? Ponieważ nie może odebrać odpowiedzi nagłówka ping z domyślnej bramy, problem zdecydowanie nie istnieje, więc jest to właściwy duży błąd błędnej konfiguracji.
Przetestujmy więc tę teorię muzyki. Zresetowałem bramę, aby osiągnąć HA do ukończenia Ustawmy nasz domyślny dostęp, który zezwala na pingi z nagłówkiem i poniżej i w dół i voila, po przeniesieniu ustawień portów konsoli serwisowej i ponownym włączeniu HA w klastrze wszystko ożyło , obie opcje hostów zostały poprawnie włączone przez HA chwilowo !!!!
 Czy
Czy
Jest to aktywność, która jest teraz wyświetlana w dzienniku, ponieważ każdy z naszych agentów HA często widzi domyślną podróż.
Aktualizacja: Po opublikowaniu tego artykułu zwróciłem się do pewnego rodzaju komentarza Duncana Eppinga, który skłonił mnie do zaawansowanego wyboru wysokiej dostępności: das. Adres izolacji.
Dodając dodatkową, oszczędzającą czas odpowiedź izolacji do zaawansowanych opcji HA, teraz możemy powiedzieć HA, aby pomyślnie korzystała z wielu różnych bram, zamiast ustawiać wartość domyślną, o której wielu z nas wie, że faktycznie zareaguje.
Dodaj korzystające wersje do okna Zaawansowane opcje HA.
- dz. Isolationaddress [x] pasuje do 10.0.0.1 (Twój dodatkowy adres odpowiedzi zdalnej lokalizacji)
- das.usedefault Isolationaddress oznacza fałszywy
Dodana przeze mnie opcja sec mówi HA, aby nie rozpoczynała pracy z bramą domyślną, hOznacza to, że właśnie dodane użycie będzie teraz używane zamiast.

Ten artykuł był i jest nadal publikowany na PlanetVM. Chcę podziękować Tomowi Howarthowi za umożliwienie mi opublikowania jego doskonałej opinii na temat wirtualizacji.
Przez kilka dni podczas tworzenia magazynu danych NFS na hoście esxi otrzymywałem podstawowy komunikat o błędzie:
Wystąpił błąd podczas tworzenia hosta.
Gdy Twoja firma często przegląda szczegóły zadania, mówi:
Proces anulowany, raport diagnostyczny: Proces Sysinfo na pewno może zostać zakończony.
Zobacz plik dziennika VMkernel, aby uzyskać więcej informacji.
Co spowodowało problem?
Ten cel błędu tak naprawdę nie pomaga i może być spowodowany różnymi problemami. Rzeczy do wypróbowania:
- Upewnij się, że FQDN urządzenia NAS można sprawdzić/poprawić podczas pracy z vCenter.
- Upewnij się, że DNS jest poprawnie skonfigurowany na rzeczywistym serwerze NAS.
- Nie zapomnij określić dokładnej lokalizacji folderu podczas dodawania repozytoriów, ale danych NAS.
- Upewnij się, że najważniejsze operacje odczytu i zapisu na urządzeniu NAS dla serwerów ESX (i) są ustawione prawidłowo — pamiętaj również, że eksperci twierdzą, że wymagany jest dostęp root.
W pracy zauważyłem, że wszystkie te problemy powodują jeden konkretny komunikat o błędzie. W moim konkretnym przypadku powiem, że u podstaw problemu leżały prawa.
© 2011 Steve Flandre Wszelkie prawa zastrzeżone.
Utwórz
Gdy magazyn danych NFS był ostatnio hostowany na ESXi, otrzymałem następujący komunikat o błędzie:
Wystąpił błąd podczas konfigurowania hosta.
Błąd procesu, raport diagnostyczny: Proces Sysinfo nie mógł zostać zakończony.
Więcej informacji znajdziesz w pliku dziennika VMkernel.
Co mogło być przyczyną obecnego błędu?
Ten post nie jest zbyt pomocny, ponieważ może powodować wiele problemów. Czego ich rodziny powinny spróbować:
- Upewnij się, że FQDN ma potencjał do sprawdzenia/rozwiązania przez urządzenie NAS z vCenter.
- Bez wątpienia upewnij się, że DNS jest prawidłowo skonfigurowany na Twoim serwerze NAS.
- Upewnij się, że wpisałeś właściwe miejsce w folderze po dodaniu magazynu danych NAS.
- Upewnij się, że ogólne uprawnienia na większości urządzeń NAS są ustawione tak, jak powinny być dla Twoich prawdziwych serwerów ESX (i) — zawsze pamiętaj, że wymagany jest dostęp do Internetu przez roota.
Osobiście odkryłem, że prawie wszystkie z tych problemów powodują wyświetlanie niektórych komunikatów o błędach. W moim konkretnym przypadku rootem związanym z problemem były uprawnienia.
Przyspiesz swój komputer już dziś dzięki temu prostemu pobieraniu.Error During Configuration Of The Host
Error Durante La Configuración Del Host
Errore Durante La Configurazione Dell’host
호스트 구성 중 오류
Fehler Bei Der Konfiguration Des Hosts
Erro Durante A Configuração Do Host
Fout Tijdens Configuratie Van De Host
Ошибка при настройке хоста
Fel Under Konfiguration Av Värden
Erreur Lors De La Configuration De L’hôte

Related posts:
 Najlepszy Sposób Na Naprawienie Dostępu Do Panelu Cpanel Dla Użytkownika Root Hosta Lokalnego
Najlepszy Sposób Na Naprawienie Dostępu Do Panelu Cpanel Dla Użytkownika Root Hosta Lokalnego
 Rozwiązanie Umożliwiające Dostęp I Konfigurację Avira Antivirus
Rozwiązanie Umożliwiające Dostęp I Konfigurację Avira Antivirus
 Najlepszy Sposób Na Odinstalowanie Sposobu Zmiany Nazwy Hosta W Systemie Windows 7
Najlepszy Sposób Na Odinstalowanie Sposobu Zmiany Nazwy Hosta W Systemie Windows 7
 Identyfikowanie I Naprawianie Błędów Zenmap Poprzez Wykonywanie Poleceń
Identyfikowanie I Naprawianie Błędów Zenmap Poprzez Wykonywanie Poleceń