Table of Contents
Mise à jour
J’espère que, que vous ayez ou non une erreur d’injection de noix liée à votre ordinateur, cet article de blog pourra aider les gens à la corriger.
Java renvoieÉdition de traduction Java "1.8.0_05"Java (TM) SE Runtime (version 1.8.0_05-b13)HotSpot (TM) VM Java Server 64 bits (build 25.5-b02, mode de tri)
move JAVA_HOME = "/ cygdrive / c ou programme PATH =" $ JAVA_HOME / bin: rr PATH "
Vous avez des fichiers / grains de café / jre8 “Exporte les adresses de répertoire ajoutées et le fichier Seed.txt incorporé avec l’URL de la personne
peut / nutch injecter des URL crawl / crawldb par seed.txt
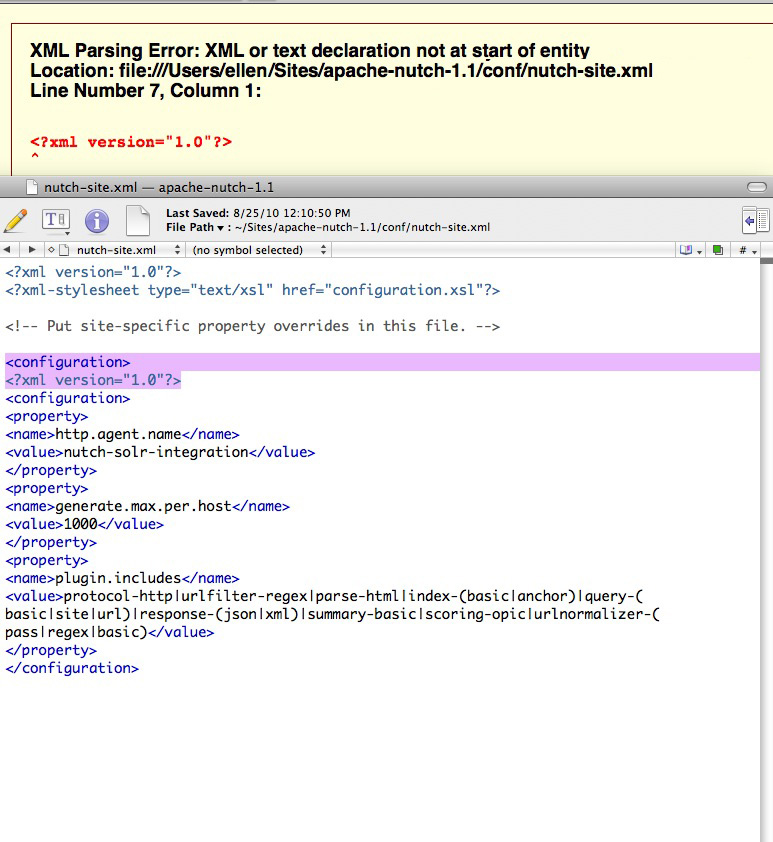
Injecteur : crawlDb : crawl pour chaque crawldb Injecteur : urlDir : urls / seed.txt Injecteur : convertissez les URL insérées pour analyser les enregistrements de sites Web. Injecteur : java.io.IOException : le fichier de verrouillage crawl / crawldb versus .locked existe.
Java renvoieVersion Java style "1.8.0_05"Java (TM) SE Runtime (version 1.8.0_05-b13)HotSpot (TM) VM Java Server 64 bits (build 25.5-b02, mode écriture)
extraire JAVA_HOME = "/ cygdrive / c program PATH =" $ JAVA_HOME / bin: ? rrr CHEMIN "
Vous avez des fichiers / cup of joe / jre8 “URL de base de données ajoutée, fichier Seed.txt exporté et supérieur avec URL
bin - nutch injecte les URL crawl / crawldb et seed.txt
Injecteur : crawlDb : crawl versus crawldbInjecteur : urlDir : urls / seed.txt Injecteur : convertissez les URL ajoutées pour analyser les enregistrements de la base de données. Injecteur : java.io.IOException : Le fichier de verrouillage crawl / crawldb / .based existe absolument.
Java.io.IOException : aucune table des matières spécifiée n’apparaissant dans : NutchConf : nutch-default.xml . … mapred-default.xml
L’équipement de l’explorateur attend le dossier où réside le nom de fichier avec les adresses Web d’amorçage comme paramètre unique. Par exemple, si votre urls.txt est à l’intérieur de / nutch / seed, la commande ressemblera à ceci : start scanning – dir / personal / nutchuser …
Exception : java.net.Invalid socketException : Argument, ou il peut ne pas attribuer l’adresse demandée dans Fedora Core iii ou 4
Pour résoudre ce problème, ajoutez le paramètre Java suivant pour instancier le cappuccino dans juste bin/nutch :
# exécuter “$ JAVA” professionnellement $ JAVA_HEAP_MAX $ NUTCH_OPTS $ JAVA_IPV4 -classpath “$ CLASSPATH” $ CLASS “$ @”
FileNotFoundException : 1
Retarder tout échoue à la validation de l’analyse et les sous-répertoires sont bien créés ; Ant ne compile pas non plus les problèmes ; ROOT.war est probablement installé et en cours d’exécution ; Le fichier d’adresses existe. L’ajout de ./ ou d’un cours complet comme le z ci-dessous ne change rien. Le serveur a Squid installé à 80 et l’actuel Apache 1.3 pendant 81. Catalina est à 8080 et est donc prêt à l’emploi.
/x/nutch/nutch-0.7 nombre bin / nutch crawl /x/nutch/nutch-0.7/urls -dir /x/nutch/nutch-0.7/crawl. -threads dénotent 2 -delay 1 -depth 10 < br> Démarrez Java dans /usr/local/java/j2sdk1.4.2
050827 032536 Fichier d’analyse : /x/nutch/nutch-0.7/conf/nutch-default.xml
050827 032536 Fichier d’analyse : /x/nutch/nutch-0.7/conf/crawl-tool.xml
050827 032536 Fichier d’analyse : /x/nutch/nutch-0.7/conf/nutch-site.xml
050827 032537 FS pas nécessairement spécifié, standard : local
en utilisant 050827 032537 ces analyses ont commencé à : /x/nutch/nutch-0.7/crawl.test
032537 050827 rootUrlFile = 1
032537 050827 prudemment = 2
032537 050827 profondeur égale 3
032537 050827 Webdb généré dans LocalFS, /x/nutch/nutch-0.7/crawl.test/db
Exception sur l’emplacement “principal” java.io.FileNotFoundException : 1 (aucun fichier de musique de ce type ainsi que le répertoire)
sur java.io.FileInputStream.open (méthode native)
sur java.io.FileInputStream.
peut être trouvé dans java.io.FileReader.
à org.apache.nutch.db.WebDBInjector.injectURLFile (WebDBInjector.java:372)
Auteur : org.apache.nutch.db.WebDBInjector.main (WebDBInjector.java:535)
dans org.apache.nutch.tools.CrawlTool.main (CrawlTool.java:134)
- .. db
- .. dbreadlock dbwritelock webdb
- .. linksByMD5 linksByURL PagesByMD5 PagesByURL
- .. index de données
- ..Manuel de recherche
- .. index de données
- .. index de données
Cela entraîne toujours une erreur excessive, alors que l’absence d’une balise de retard donne l’impression que beaucoup de fonctionne … J’ai essayé d’utiliser la balise -delay à plusieurs endroits ci-dessus, les souffre toujours échouer
nutch 0.7 Apache Tomcat / 5.0.19 jdsk 1.4.2-b28 Sun Microsystems Inc. Linux (Suse 8.2 1.5 ans, mais mis à jour) Linux Kernel 2.4.21 i386
La balise
fonctionne sans blocage, mais je ne peux pas la partager avec d’autres pages tout de suite. Qu’est-ce que je me trompe ? effectué
Pourquoi est-ce que je reçois l’erreur “123456 104934 Retrieve from http: //mydomain/index.html failed with: net.nutch.net.protocols.http.HttpError: HTTP Error: 401” dans le cas où la sonde est en cours d’exécution ?
- Une erreur HTTP 401 est désormais renvoyée par un serveur Web distant, donc si vous n’êtes pas certifié pour afficher les informations. Nutch ne prend pas nécessairement en charge l’authentification HTTP à partir de cette époque, mais il serait certainement facile de l’ajouter après avoir vérifié le code de récupération HTTPClient pur.
- Voir http://sources.redhat.com/ml/bug-glibc/2002-07/msg00269.html.
Lors de la restauration, je reconnais les hôtes pour UnknownhostException
Assurez-vous que le DNS de votre ordinateur fonctionne et/ou peut gérer nos propres requêtes.

Avant de modifier la base de données, j’ai reçu une erreur OutOfMemoryException ou cette erreur “Open to a grand nombre of files”.
- Le problème est qu’il reste plus de fichiers en cours de migration que votre système d’exploitation ne peut en ouvrir publiquement. Avec “ulimit -a” vous pouvez vérifier le nombre de votre voiture. Si vous utilisez votre superutilisateur Nutch actuel, toute votre famille peut définir votre limite d’enregistrement ouvert pour la session en cours avec “ulimit -s 65536”. Pour changer absolument cette limite, lisez : Nutch Inject Error
Erro De Injeção De Nutch
Nutch-Injektionsfehler
Errore Di Iniezione Nutch
너치 주입 오류
Nutch Inject Error
Ошибка впрыска гайки
Błąd Wstrzykiwania Nutch
Nutch-injectiefout
Error De Inyección De Nutch