Table of Contents
Updated
Hope that if you are having a nut injection error on your computer, this blog post can help you fix it.
Java returnsJava translation version "1.8.0_05"Java (TM) SE Runtime (build 1.8.0_05-b13)HotSpot (TM) 64-bit Java Server VM (build 25.5-b02, sort mode)
export JAVA_HOME = "/ cygdrive / c / program PATH =" $ JAVA_HOME / bin: $ PATH "
You have files / java / jre8 “Exports added directory addresses and added Seed.txt file with person url
bin / nutch inject crawl / crawldb urls / seed.txt
Injector: crawlDb: crawl / crawldb Injector: urlDir: urls / seed.txt Injector: Convert inserted URLs to scan database records. Injector: java.io.IOException: The crawl / crawldb / .locked lock file does exist.
Java returnsJava version version "1.8.0_05"Java (TM) SE Runtime (build 1.8.0_05-b13)HotSpot (TM) 64-bit Java Server VM (build 25.5-b02, write mode)
export JAVA_HOME = "/ cygdrive / c / program PATH =" $ JAVA_HOME / bin: $ PATH "
You have files / java / jre8 “Added database url, exported and added Seed.txt file with url
bin / nutch inject crawl / crawldb urls / seed.txt
Injector: crawlDb: crawl / crawldbInjector: urlDir: urls / seed.txt Injector: Convert inserted URLs to scan database records. Injector: java.io.IOException: The lock file crawl / crawldb / .locked absolutely exists.
Hello,> "chmod"
Java.io.IOException: No table of contents specified in: NutchConf: nutch-default.xml. … mapred-default.xml
The explorer tool expects the folder where the filename is located with the bootstrap web addresses as an initial parameter. For example, if your urls.txt is in / nutch / seed, the command will look like this: start scanning – dir / user / nutchuser …
Exception: java.net.Invalid socketException: Argument, or it cannot assign the requested address in Fedora Core 3 or 4
To solve this problem, add the following Java parameter to instantiate cappuccino in bin / nutch:
# run “$ JAVA” professionally $ JAVA_HEAP_MAX $ NUTCH_OPTS $ JAVA_IPV4 -classpath “$ CLASSPATH” $ CLASS “$ @”
FileNotFoundException: 1
Delay 1 fails scan validation and subdirectories are created as well; Ant also doesn’t compile problems; ROOT.war is installed and running; The address file exists. Adding ./ or a full course like the x below doesn’t change anything.The server has Squid installed at 80 and the actual Apache 1.3 at 81. Catalina is at 8080 and is therefore ready to use.
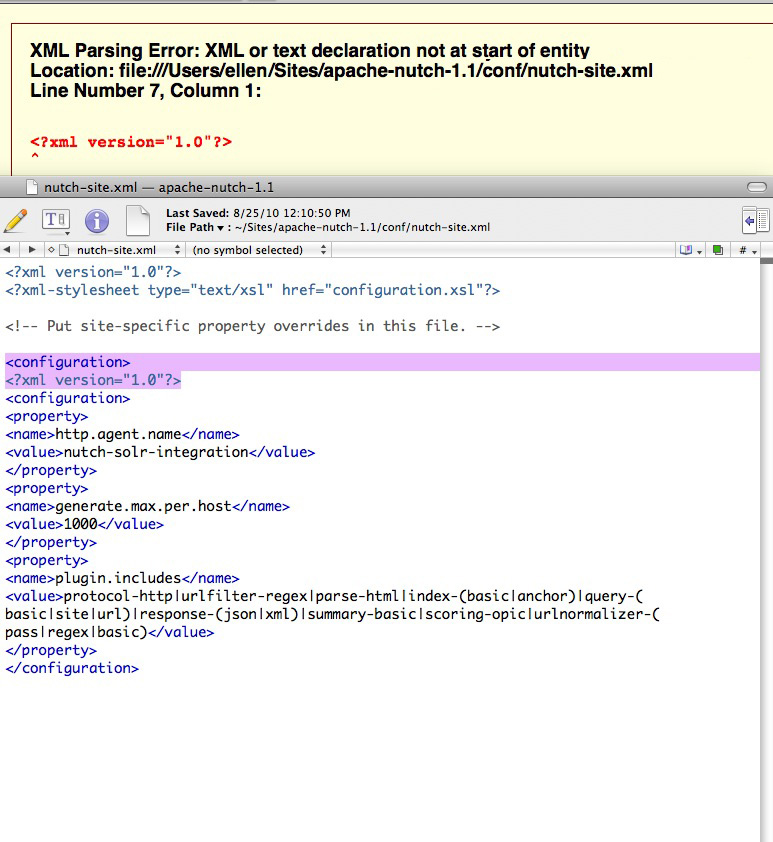
/x/nutch/nutch-0.7 # bin / nutch crawl /x/nutch/nutch-0.7/urls -dir /x/nutch/nutch-0.7/crawl.-threads define 2 -delay 1 -depth 10 < br> Start Java in /usr/local/java/j2sdk1.4.2
050827 032536 Analysis file: /x/nutch/nutch-0.7/conf/nutch-default.xml
050827 032536 Analysis file: /x/nutch/nutch-0.7/conf/crawl-tool.xml
050827 032536 Analysis file: /x/nutch/nutch-0.7/conf/nutch-site.xml
050827 032537 FS not specified, standard: local
using 050827 032537 the scan started at: /x/nutch/nutch-0.7/crawl.test
032537 050827 rootUrlFile = 1
032537 050827 thread = 2
032537 050827 depth = 3
032537 050827 Webdb generated in LocalFS, /x/nutch/nutch-0.7/crawl.test/db
Exception on “main” thread java.io.FileNotFoundException: 1 (no such music file or directory)
at java.io.FileInputStream.open (native method)
at java.io.FileInputStream.
can be found in java.io.FileReader.
at org.apache.nutch.db.WebDBInjector.injectURLFile (WebDBInjector.java:372)
Author: org.apache.nutch.db.WebDBInjector.main (WebDBInjector.java:535)
at org.apache.nutch.tools.CrawlTool.main (CrawlTool.java:134)
- .. db
- .. dbreadlock dbwritelock webdb
- .. linksByMD5 linksByURL PagesByMD5 PagesByURL
- .. data index
- ..Research Handbook
- .. data index
- .. data index
This always results in an over-error, while missing a delay tag gives the impression that works … I’ve tried using the -delay tag in several places above, it always suffers fail
nutch 0.7 Apache Tomcat / 5.0.19 jdsk 1.4.2-b28 Sun Microsystems Inc. Linux (Suse 8.2 1.5 years, but updated) Linux Kernel 2.4.21 i386
The
tag works without delay, but I can’t share it with other sites right away. What am I wrong? do
Why am I getting the error “123456 104934 Retrieve from http: //mydomain/index.html failed with: net.nutch.net.protocols.http.HttpError: HTTP Error: 401” in the case when the probe is running ?
- An HTTP 401 error is returned from a remote web server if you are not certified to view the page. Nutch does not necessarily support HTTP authentication at this time, but it would certainly be trivial to add it after checking the pure HTTPClient fetch code.
- See http://sources.redhat.com/ml/bug-glibc/2002-07/msg00269.html.
When Restoring, I Recognize Hosts For UnknownhostException
Make sure your computer DNS is working and / or can handle our own requests.

Before updating the database, I received an OutOfMemoryException or an “Open to a large number of files” error.
- The problem is that more files are being migrated than your operating system can open. With “ulimit -a” you can check the number of your car. If you are using the Nutch superuser, your entire family can set the open record limit for the current session using “ulimit -s 65536”. To change this limit permanently, read: Erro De Injeção De Nutch
Erreur D’injection De Noix
Nutch-Injektionsfehler
Errore Di Iniezione Nutch
너치 주입 오류
Nutch Inject Error
Ошибка впрыска гайки
Błąd Wstrzykiwania Nutch
Nutch-injectiefout
Error De Inyección De Nutch