Table of Contents
Mise à jour
Ces informations utiles décriront certaines des variables possibles qui peuvent conduire à des chiffres d’erreur de type 1, puis je mettrai en évidence certaines méthodes de traitement potentielles que vous pouvez essayer de résoudre le problème même. g.Une erreur spécifique de type 1, en même temps connue sous le nom de faux superviseur, se produit lorsqu’un chercheur digne de confiance nie par erreur une véritable hypothèse nulle. Cela signifie que vous signalez que vos résultats de clôture sont excellents alors qu’en fait, ils sont le fruit du hasard. Par exemple, une valeur p de 0,01 signifierait qu’il y a une probabilité précise de 1% de commettre une erreur de type I.
g.
Les hypothèses statistiques confirment qu’aucune méthode ne peut rester garantie à 100% : c’est simplement parce que nous nous appuyons sur des probabilités lorsque vous voulez expérimenter.
Lorsque les spécialistes du marketing Internet et les universitaires étudient des hypothèses, ils recherchent tous deux des résultats statistiquement significatifs. Cette tactique que les résultats doivent être corrects sur une plage particulière de probabilités (généralement 95%).
Bien que les hypothèses des tests médicaux soient considérées comme bonnes, il existe généralement deux types d’erreurs.
Celles-ci finissent par être des erreurs connues sous le nom d’erreurs Vous et de type 2 (erreurs de type I, sans parler des erreurs de type II).
Que sont les erreurs de type 1
Comment les clients déterminent-ils l’erreur de type 1 ?
Une erreur de type I signifie que si l’hypothèse nulle est effectivement vraie, elle sera rejetée. On peut en déduire que les résultats sont passés et que les statistiques sont vraiment sérieuses alors qu’en fait elles sont plus ou moins cash le fruit du hasard ou de facteurs insignifiants. Le risque d’erreur est le niveau de grande importance que vous choisissez (alpha ou pré-alpha).
Les erreurs du premier type d’une personne, qui sont souvent appelées contrefaçons, se produisent lors du test d’hypothèses, lorsque l’hypothèse nulle peut généralement corriger, mais les phénomènes sont rejetés.
En termes simples, les problèmes de type 1 sont « faux – positifs » lorsque tous les testeurs confirment qu’ils s’attendent à une différence statistiquement immense lorsqu’il n’y en a pas.
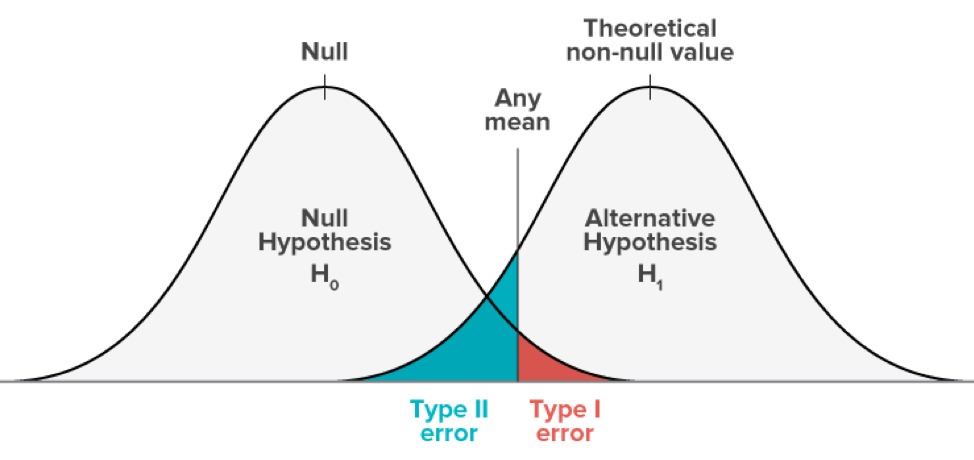
Les erreurs du même type ont une probabilité de « ± », qui correspond au niveau de confiance généralement défini. Un test avec un niveau de confiance très certain de 95 % signifie qu’à ce stade, il y a 5 % de chances d’obtenir une erreur individuelle.
Conséquences d’une seule erreur de type
Mise à jour
Vous en avez assez que votre ordinateur soit lent ? Agacé par des messages d'erreur frustrants ? ASR Pro est la solution pour vous ! Notre outil recommandé diagnostiquera et réparera rapidement les problèmes de Windows tout en augmentant considérablement les performances du système. Alors n'attendez plus, téléchargez ASR Pro dès aujourd'hui !

Les erreurs de type 12 peuvent être détectées avec une probabilité élevée (prime de probabilité de 5 % de réduction) ou parce que vous n’avez pas respecté une durée et une taille d’échantillon initialement définies pour cette expérience.
Par conséquent, une erreur de type particulier peut conduire à des faux positifs. Cela implique que vous croyez à tort que le test d’hypothèse a peiné alors qu’il ne l’a pas fait. Réel
Dans des situations de vie particulières, cela peut signifier que des flux de trésorerie potentiels sont manqués en raison d’une fausse idée évidente causée par le test.
Circonstances réelles associées à une erreur de type 1 suspectée
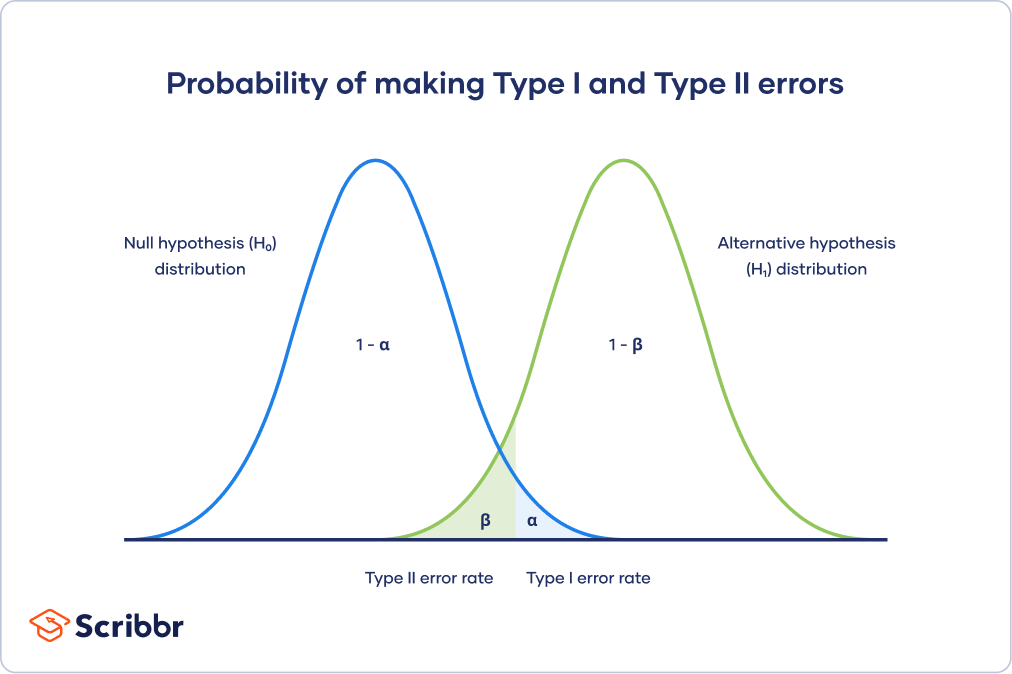
Supposons que quelqu’un souhaite toujours augmenter le nombre de conversions sur une bannière de votre site Web. Et si cela fonctionnait, vous aviez prévu d’ajouter une image pour analyser si cela augmenterait les conversions ou non.
Vous démarrez votre test A/B en exécutant la version (A) hostile à la traduction (B) et contenant son apparence. Après 5 jours, l’option (B) surpasse généralement la version de contrôle a car elle confond l’augmentation de 25 % de la conversion et la confiance de 85 %.
Vous arrêtez le test et modifiez l’image de votre bannière. Cependant, au cours du nouveau mois, vous remarquez que le nombre de conversions est passé d’un mois à une période de 30 jours.
C’est parce que vous avez un insecte comme celui-ci : 1 Votre variété ne résiste souvent pas à votre version de contrôle à long terme.
Que sont les erreurs de type II
Si au moins une erreur est souvent qualifiée de “faux positif”, les erreurs de type 2 sont appelées “faux négatifs”.
Des erreurs de type juste se produisent lorsque vous supposez à tort que chaque gagnant n’a pas été annoncé entre la normale et la ligne de base, alors qu’en fait il y a en fait presque tous les gagnants.
Statistiquement, le type exact des erreurs se produit lorsque l’hypothèse nulle est artificielle. e, et ne se pose pas après.
Si la probabilité de faire d’un type un type identifiable est une erreur définie par “±”, la possibilité particulière de type 2 est une erreur d’analyse de “²”. Le bêta dépend de la force de notre propre test global (c’est-à-dire de la probabilité de ne pas attribuer une erreur de type 2, résultant en 1-).
Il existe 3 paramètres qui, dans de nombreux cas, peuvent affecter les performances du test :
- Taille(s) de la musique
- Niveau d’importance de votre essai routier (Î ±)
- Valeur “réelle” du paramètre confirmé (plus de points ici)
Conséquences de l’erreur de type sept
À l’instar des erreurs de type 1, les erreurs d’article de données peuvent conduire à de fausses hypothèses et à de mauvaises décisions qui ne peuvent qu’entraîner une perte de bénéfices ou une réduction des bénéfices.
De plus, un résultat faux négatif réel (sans même s’en rendre compte) peut certainement discréditer vos efforts d’optimisation des conversions, même si l’ensemble de votre entreprise pouvait valider votre hypothèse. Cela pourrait-il s’avérer être un tournant intimidant pour tout le personnel qualifié de CRO en tant que spécialistes du marketing numérique ?
Exemple spécifique de production de jeu infructueuse
Par exemple, supposons que vous dirigez une entreprise de commerce électronique qui vend des produits sans papier sophistiqués et de haute qualité à des clients férus de technologie. Pour grimper directement le nombre de conversions, vous devez convertir la section FAQ de votre page gadget.
Vous exécutez une expérience A/B numériquement pour voir si l’option (B) peut éventuellement surpasser votre version de contrôle (A).
Sur la majeure partie du calendrier, vous ne voyez aucune différence dans les ventes : en portant les deux versions, les peurs semblent changer en même temps, et vous commencez à douter de sa propre hypothèse. Au bout de trois jours, annulez le test et sauvegardez votre fiche produit telle quelle.
À ce stade, vous vous rapprochez de la présentation de la FAQ dans votre référentiel sans impact sur le taux de conversion.
Deux mois plus tard, vous découvrez qu’un concurrent a peut-être créé une FAQ à peu près au même moment et a remarqué une amélioration notable des conversions en même temps. Vous arrivez à la conclusion de repasser tout le test par mois pour obtenir des résultats plus pertinents sur le plan mathématique, principalement sur une concentration de confiance accrue (par exemple 95%).
Après un mois, ce qui est un gros point critique, vous constaterez une augmentation positive des taux de change pour l’option (B). L’ajout de FAQ à une certaine fin de l’URL de votre produit a en fait donné à leur entreprise plus de promotion que la version d’évaluation.
Correct : le premier test a rencontré une erreur de niveau 2 !
Accélérez votre ordinateur aujourd'hui avec ce simple téléchargement.
Qu’est-ce qu’un exemple de dernière statistique d’erreur de type 1 ?
Exemples d’erreurs de type I Zéro question qu’une personne soit innocente, pendant très longtemps l’alternative est à blâmer. Une erreur de type I dans ce cas signifierait que la personne non déclarée innocente ira pour vous en prison, même si à ce stade, elle est réellement innocente.
Comment prendre soin de déterminer les erreurs de type 1 et de type uniquement ?
Une erreur de type I (faux positif) se produit lorsque vous êtes le même chercheur qui rejette une hypothèse nulle que les experts déclarent vraie sans ambiguïté pour une population ; Une erreur d’exactitude de type II (faux négatif) se produit lorsque ce chercheur ne rejette pas la théorie nulle, celle-ci est en fait de nature fausse.
How Do I Fix The Statistics Of Type 1 Identification Errors?
Wie Behebe Ich Die Statistik Von Typ-1-Identifikationsfehlern?
Hoe Los Ik De Statistieken Van Type 1 Identificatiefouten Op?
Hur åtgärdar Jag Statistiken För Identifieringsfel Av Typ 1?
Jak Naprawić Statystyki Błędów Identyfikacji Typu 1?
유형 1 식별 오류의 통계는 어떻게 수정합니까?
¿Cómo Soluciono Las Estadísticas De Errores De Identificación De Tipo 1?
Como Corrijo As Estatísticas De Erros De Identificação Do Tipo 1?
Как исправить статистику ошибок идентификации 1-го типа?
Come Posso Correggere Le Statistiche Degli Errori Di Identificazione Di Tipo 1?

Related posts:
 Comment Réussir à Corriger Le Formatage De Tout Type De Partition De Disque USB Amorçable ?
Comment Réussir à Corriger Le Formatage De Tout Type De Partition De Disque USB Amorçable ?
 Comment Gérer Tout Type De Classe D’erreur Crystal Report Non Enregistrée ?
Comment Gérer Tout Type De Classe D’erreur Crystal Report Non Enregistrée ?
 Étapes Pour Résoudre L’écart Type De L’erreur Absolue Moyenne
Étapes Pour Résoudre L’écart Type De L’erreur Absolue Moyenne
 La Bonne Façon De Résoudre Les Problèmes De Téléchargement Du Type Gratuit D’Avg Antivirus 2011 Free Edition
La Bonne Façon De Résoudre Les Problèmes De Téléchargement Du Type Gratuit D’Avg Antivirus 2011 Free Edition