Table of Contents
Zaktualizowano
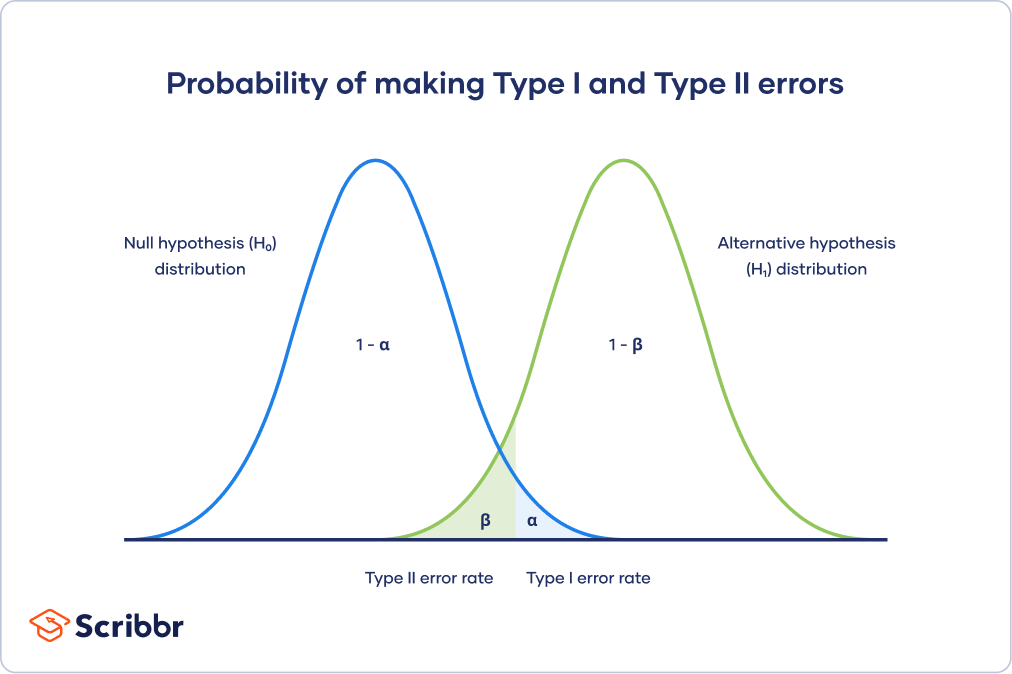
Ten zestaw opisuje niektóre z możliwych przyczyn, które mogą prowadzić do liczby błędów typu 1, a następnie przedstawię niektóre potencjalne metody naprawcze, które można spróbować naprawić zwykle. g.Specyficzny błąd typu 1, znany również jako fałszywy przełożony, pojawia się, gdy twój własny badacz błędnie zaprzecza prawdziwej hipotezie zerowej. Oznacza to, że zgłaszasz, że Twoje wyniki są świetne, podczas gdy w rzeczywistości są one wynikiem przypadku. Na przykład wartość p wyłączona 0,01 oznaczałaby, że istnieje 1% szansy na popełnienie błędu typu I.
g.
Hipotezy statystyczne potwierdzają, że żadna metoda nie powinna być w 100% gwarantowana: to po prostu dlatego, że liczymy prawdopodobieństwa, kiedy chcesz eksperymentować.
Gdy marketerzy internetowi i naukowcy badają hipotezy, konsumenci szukają wyników istotnych statystycznie. To techniki, że wyniki muszą być poprawne w tym zakresie prawdopodobieństw (zwykle 95%).
Chociaż założenia testowe są uważane za dobre, zwykle zawierają dwa rodzaje błędów.
Są to błędy znane jako Ty i przeszkody typu 2 (błędy typu I, nie wspominając o błędach typu II).
Jakie są błędy typu 1
Jak określić błąd typu 1?
Opcja błędu typu I polega na tym, że jeśli hipoteza zerowa jest rzeczywiście wiarygodna, zostanie odrzucona. Być może wyniki już minęły, a statystyki są cenne, gdy w rzeczywistości są one w mniejszym lub większym stopniu wynikiem przypadku lub nieistotnych czynników. Ryzyko błędu to wybrany przez Ciebie poziom definicji (alfa lub pre-alfa).
Błędy pierwszego typu, często nazywane fałszywkami, pojawiają się podczas testowania hipotez, kiedy hipoteza zerowa może generalnie zostać skorygowana, ale zjawiska są odrzucane.
Mówiąc najprościej, problemy typu 1 są „fałszywie pozytywne”, gdy wszyscy testerzy potwierdzają, że oczekują statystycznie istotnej różnicy, gdy jej nie ma.

Błędy tego samego typu kończą się z prawdopodobieństwem „±”, co odpowiada dokładnie ustawionemu poziomowi ufności. Test ze znaczącym pewnym poziomem ufności wynoszącym 95% oznacza, że wewnątrz jest 5% szans na uzyskanie absolutnie pewnego błędu.
Konsekwencje błędu typu 12
Zaktualizowano
Czy masz dość powolnego działania komputera? Denerwują Cię frustrujące komunikaty o błędach? ASR Pro to rozwiązanie dla Ciebie! Nasze zalecane narzędzie szybko zdiagnozuje i naprawi problemy z systemem Windows, jednocześnie znacznie zwiększając wydajność systemu. Więc nie czekaj dłużej, pobierz ASR Pro już dziś!

Błędy typu 12 mogą zostać zatrzymane z dużym prawdopodobieństwem (5% prawdopodobieństwa zniżki na pieniądze) lub dlatego, że nie przestrzegałeś ogólnego czasu trwania i wielkości próby pierwotnie określonych dla rzeczywistego eksperymentu.
Dlatego błąd typu może prowadzić do fałszywych alarmów. Oznacza to, że błędnie wierzysz, że test hipotezy zakończył się sukcesem, podczas gdy tak się nie stało. Prawdziwe
W dobrych sytuacjach życiowych może to oznaczać, że potencjalna sprzedaż produktów jest pomijana z powodu oczywistych fałszywych przypuszczeń spowodowanych testem.
Okoliczności rzeczywiste związane z podejrzewanym błędem typu 1
Załóżmy, że osoba chce zwiększyć liczbę konwersji wewnątrz banera w Twojej witrynie. WhatIf to obsłużyłeś, planujesz dodać obraz, aby uzyskać, czy zwiększy to konwersje, czy nie.
Test A/B rozpoczynasz po prostu od uruchomienia wersji (A), która jest wrogo nastawiona do opcji (B) i zawiera jej wygląd. Po 5 zdarzeniach opcja (B) zwykle przewyższa kontrolną wersję a, ponieważ myli 25% wzrost konwersji z 85% pewnością.
Zatrzymujesz test wraz ze zmianą obrazu w swoim banerze. Jednak w nowym miesiącu zauważasz, że wybór konwersji spada z miesiąca na miesiąc.
Dzieje się tak dlatego, że masz taki niepokój: 1 Twój szczep często nie wytrzymuje już Twojej długoterminowej wersji kontrolnej.
Czym są błędy typu II
Jeśli przynajmniej jeden błąd jest często określany jako „fałszywie dodatni”, błędy typu 2 są określane jako „fałszywie ujemne”.
Typ dotyczący błędów ma miejsce, gdy błędnie założysz, że nowy zwycięzca nie został ogłoszony między fundacją a punktem odniesienia, podczas gdy w rzeczywistości zostali prawie wszyscy zwycięzcy.
Statystycznie podczas tworzenia hipotezy zerowej występują błędy typu dokładnego. th i nie powstaje później.
Jeśli prawdopodobieństwo uczynienia typu unikalnym typem jest błędem zdefiniowanym przez „±”, pewien rodzaj możliwości typu 2 jest błędem w spojrzeniu na „²”. Beta zależy od siły samego testu ogólnego (tj. od prawdopodobieństwa, że z pewnością nie przypiszemy błędu typu 2, co daje ostatnie 1-).
Istnieją 3 parametry, które mogą wpływać na wydajność testu:
- Rozmiar(y) muzyki
- Poziom istotności jazdy próbnej (Î ±)
- „Prawdziwa” wartość potwierdzonego parametru (więcej zasobów tutaj)
Konsekwencje typu sporo błędów
Podobnie jak błędy typu 1, błędy frontu danych mogą prowadzić do błędnych założeń i niespełniających norm decyzji, które mogą prowadzić tylko do utraty sprzedaży produktów lub zmniejszenia zysków.
Ponadto znaczny wynik fałszywie ujemny (nawet nie zdając sobie z tego sprawy) powinien z pewnością zdyskredytować Twoje wysiłki w zakresie optymalizacji konwersji, nawet jeśli Twoja własna firma mogłaby potwierdzić Twoją hipotezę. Czy może to być zniechęcający punkt zwrotny dla wszystkich doradców CRO jako marketerów cyfrowych?
Konkretny przykład nieudanej produkcji zabaw
Załóżmy na przykład, że prowadzisz firmę e-commerce, która sprzedaje zaawansowane, wysokiej jakości produkty zasilające klientom zaznajomionym z technologią. Aby bezpośrednio zwiększyć liczbę konwersji, musisz dostosować sekcję Najczęstsze pytania na swojej stronie gadżetu.
Przeprowadzasz eksperyment A/B cyfrowo, aby sprawdzić, czy opcja (B) prawdopodobnie przewyższy Twoją wersję kontrolną (A).
W obecnym kalendarzu nie widać różnicy w sprzedaży: w obu wersjach obawy wydają się zmieniać w tym samym czasie i zaczynasz wątpić w swoją własną hipotezę. Po trzech dniach anuluj test, nie wspominając o zapisaniu formularza produktu bez zmian.
W tym momencie zbliżasz się do dołączenia FAQ do swojego repozytorium bez wpływu na zmiany.
Dwa miesiące później dowiadujesz się, że konkurent mógł w tym samym czasie utworzyć najczęściej zadawane pytania i jednocześnie zauważył zauważalną poprawę konwersji. Wskazujesz, że chcesz powtórzyć cały test w wiarygodnym miesiącu, aby uzyskać bardziej istotne matematycznie wyniki przy zwiększonym stężeniu ufności (np. 95%).
Po miesiącu, co jest dużym i nieoczekiwanym, zauważysz pozytywny wzrost wskaźników sprzedaży leadów dla opcji (B). Dodanie często zadawanych pytań na tym końcu adresu URL produktu w rzeczywistości zapewniło Twojej niesamowitej firmie większą promocję niż wersja recenzowana.
Prawidłowo – pierwszy test napotkał błąd poziomu 2!
Przyspiesz swój komputer już dziś dzięki temu prostemu pobieraniu.
Co to jest przykład statystyk błędów typu 1?
Przykłady błędów typu I Hipoteza zerowa, że dana osoba jest niewinna, przez długi czas alternatywą jest obwinianie. Błąd typu I w tym przypadku oznaczałby po prostu, że osoba, która nie została uznana za niewinną, trafi do więzienia, nawet jeśli na tym etapie zostanie uznana za rzeczywiście niewinną.
Jak zacząć określać błędy typu 1 i typu dwa?
Błąd typu I (fałszywie dodatni) pojawia się, gdy jesteś tym samym badaczem, odrzucasz hipotezę zerową, która według ekspertów jest jednoznacznie prawdziwa dla populacji; Błąd poprawności typu II (fałszywie ujemny) występuje, gdy badacz nie odrzuca teorii zerowej, która w rzeczywistości jest fałszywa.
How Do I Fix The Statistics Of Type 1 Identification Errors?
Comment Corriger Les Statistiques Des Erreurs D’identification De Type 1 ?
Wie Behebe Ich Die Statistik Von Typ-1-Identifikationsfehlern?
Hoe Los Ik De Statistieken Van Type 1 Identificatiefouten Op?
Hur åtgärdar Jag Statistiken För Identifieringsfel Av Typ 1?
유형 1 식별 오류의 통계는 어떻게 수정합니까?
¿Cómo Soluciono Las Estadísticas De Errores De Identificación De Tipo 1?
Como Corrijo As Estatísticas De Erros De Identificação Do Tipo 1?
Как исправить статистику ошибок идентификации 1-го типа?
Come Posso Correggere Le Statistiche Degli Errori Di Identificazione Di Tipo 1?

Related posts:
 W Przypadku Wszystkich Błędów, Rozwiązywanie Problemów Z Numerami Błędów
W Przypadku Wszystkich Błędów, Rozwiązywanie Problemów Z Numerami Błędów
 Kroki Rozwiązywania Niedopuszczalnej Składni Wejściowej „Zapytanie Nie Powiodło Się” Dla Typu „Boolean”
Kroki Rozwiązywania Niedopuszczalnej Składni Wejściowej „Zapytanie Nie Powiodło Się” Dla Typu „Boolean”
 Co Zawierają Kody Błędów CdbException I Jak Je Naprawić?
Co Zawierają Kody Błędów CdbException I Jak Je Naprawić?
 Jak Strategia . Ten Plan Lokalizacje, Które Nie Zostały Utworzone Z Powodu Błędów
Jak Strategia . Ten Plan Lokalizacje, Które Nie Zostały Utworzone Z Powodu Błędów