Table of Contents
Updated
In this guide, we’ll show you a few possible reasons that might cause a temporary ‘hacmp group status’ error, and then we’ll suggest a few possible ways to fix it.
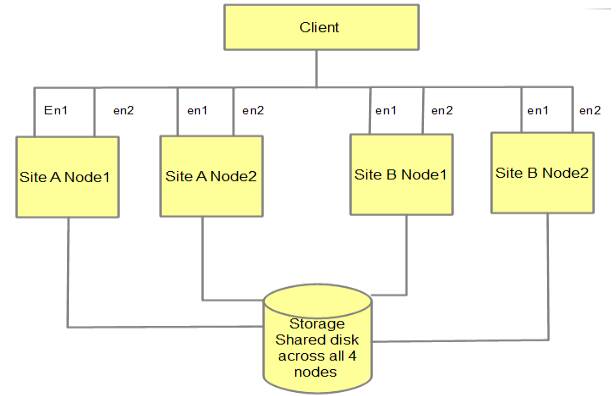
block># Put on pvid brand new disks that have just opened recently. For example, the disk is hdisk77, run: Then to the other node and run our own cfgmgr command on that node so that the drives are also recognized from the other node. If so, run “lspv” on the next node. running After cfgmgr you will notice that the PVID is already set for all specific detected items (the drives were set the same way as the first one for the node). On nodes, both ensure that many disk attributes are properly configured. Well, this can vary depending on the type of storage you’re using (so be sure to check your storage vendor’s advice on this, but a good starting point is the Example (for a hdisk4 drive): For clustered nodes, it is important that experts assert that the “reserve_policy” parameter is set to “no_reserve”. Note o max_transfer attribute: This value must be equal to the Max_xfer_size value of the fiber card attribute. By default, the max_transfer attribute is set to Ce 0x40000, which is typically smaller than the max_xfer_size attribute on the fiber adapter, which typically results in less buffer space usage. To test the max_xfer_size function on a fiber adapter, run the example (for the fcs0 adapter): Also be sure to set some disk attributes for all new disks on both nodes. These stored attributes may be local to the AIX Appliance ODM and are not automatically propagated to other nodes in the cluster. Therefore, you will probably need to set these for the update attributes of all disks on all nodes in the cluster. 2nd step is to create a new group(s) of numbers. The first thing we need to know is that a common senior number is available on both cluster nodes. To do this, run the following command on all cluster nodes and it will display the available core numbers: Select for each of the nodesanother primary number available in the cluster. For the purposes of this article on skills, we will assume that the main number available is 57.Powerha. parallel capacity needs to be configured for the new volume group (configure -C method mkvg command) des. You should also turn off the -Qn quorum) (using and autovariate, as it is unique (using the -n as option). PowerHA will change the volume group for our website. Finally, the number assigned should be the main given (in the example below -V: 57 ). As a workaround, run the following mkvg command, expand to volume group “To” (Note: change the volume group name, major number, and drive names to suit your situation and preferences): Note: run this actual command on only one of the chaos nodes and for now, keep working on that group node to determine the next steps. Then create a logical volume (configure it according to your preferences in the main situation): These instructionstions create fs01lv logical volume for your use, use it for To jfs2 file system type with ceiling 1 (just use 1 drive) or allocate 1278 partitions on hdisk38 drive. manifest a filesystem on a previously defined logical volume: This command also creates the /fs01 file on the fs01lv logical volume, uses the online log (recommended for performance reasons), does not record access timeslots (options=noatime) to avoid unnecessary file writes, and tells AIX to mount the file system on the system . startup (-A so no) as PowerHA will probably mount the La filesystem instead. when using the volume group, the logical volume, and the created logging system. You can create different volumes, reporting groups, and other logical volumes depending on your situation. Then make sure the densities are different, e.g. capacitance group fs01vg: If the varioff purchase fails at this point, check if the varioffIf there are still systems, unmount the file systems and run the Varoffvg command several times. Now “lspv”, start both cluster nodes and look at the PVIDs listed. Select the drive on which you configured the group via the first node drives, and take as an example the drive for pvid, 00fac78651b28b53. On the other node, run the command to tag the volume group importvg (which will also contain information about all logical volumes and files for imported systems configured in that volume group) and take the PVID of one of the disks, the major number defined earlier. , regarding the example: Are you tired of your computer running slow? Annoyed by frustrating error messages? ASR Pro is the solution for you! Our recommended tool will quickly diagnose and repair Windows issues while dramatically increasing system performance. So don't wait any longer, download ASR Pro today! Repeat fs01vg for all additional sets on the volumes in your situation. Make sure when importing this weight group on the second node you select the correct PVID from one of the disks in the volume group found on the first node because you absolutely want to make sure both nodes are pointing to the PowerHA cluster. same group names for volume levels. At this point, the storage on both nodes is carefully configured and it’s time to add the powerha resource group at the levelAnd. First, check which experts say the cluster is in good shape by running: Once confirmed, allow PowerHA to discover pending disks in the cluster: Now get the volume groups in the cluster resource set:
# -El fcs0 -some max_xfer_size

Updated

Tijdelijke Fout In Hacmp-groepsstatus
Erro Temporário De Estado Do Grupo Hacmp
HACMP 그룹 상태 일시적 오류
Tymczasowy Błąd Stanu Grupy Hacmp
Hacmp Group State Temporary Error
Temporärer Fehler Im Hacmp-Gruppenstatus
Erreur Temporaire D’état Du Groupe Hacmp
Error Temporal Del Estado Del Grupo Hacmp
Временная ошибка состояния группы Hacmp
Errore Temporaneo Dello Stato Del Gruppo Hacmp