Table of Contents
Zaktualizowano
W tym przewodniku przedstawimy kilka możliwych powodów, dla których może wystąpić tymczasowy błąd „hamp group status”, a także wtedy zasugerujemy kilka możliwych odpowiedzi, aby to naprawić.
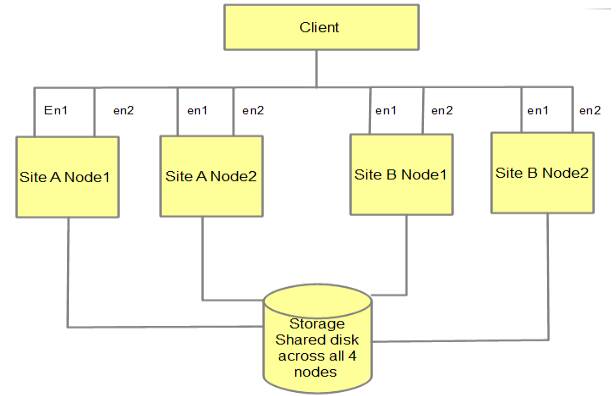
blok># Załóż nowe dyski Pvid, które, szczerze mówiąc, niedawno się otworzyły. Na przykład dysk został hdisk77, uruchom: Następnie przejdź do drugiego węzła i uruchom na tym węźle nasze niezwykle cfgmgr polecenie, aby wszystkie dyski były również rozpoznawane z innych rodzajów węzłów. Jeśli tak, uruchom „lspv” w następującym węźle. running Po cfgmgr zauważysz, że te identyfikatory PVID są już ustawione dla wszystkich określonych wykrytych elementów (napędy zostały ustawione tą samą metodą, co pierwsza dla węzła). W węzłach obie opcje zapewniają dokładne skonfigurowanie wielu atrybutów dysku. Cóż, może się to różnić w zależności od rodzaju używanej pamięci masowej (więc koniecznie sprawdź porady dostawcy pamięci masowej dotyczące tego procesu, ale dobrym punktem wyjścia jest przykład (dla dysku hdisk4): W przypadku zgrupowanych węzłów ważne jest, aby eksperci twierdzili, że parametr „reserve_policy” jest ustawiony na faktycznie „no_reserve”. Uwaga o atrybucie max_transfer: ta wartość musi być stale równa wartości Max_xfer_size atrybutu karty bielizny. Domyślnie atrybut max_transfer jest ustawiony na Ce 0x40000, który jest zazwyczaj mniejszy niż atrybut max_xfer_size na karcie światłowodowej, co zazwyczaj skutkuje implementacją mniejszej ilości miejsca w buforze. Aby przetestować funkcję max_xfer_size na adapterze puszki, uruchom przykład (dla adaptera fcs0): Upewnij się również, że ustawiłeś niektóre atrybuty dysku, aby pasowały do wszystkich nowych dysków w obu węzłach. Te ukryte atrybuty mogą być lokalne dla ODM urządzenia AIX i nie są automatycznie propagowane do różnych węzłów w klastrze. Dlatego praktycznie będziesz musiał ustawić je dla końca aktualizacji wszystkich dysków na wszystkich węzłach w jego klastrze. Drugim krokiem jest utworzenie nowo zakupionych grup numerów. Pierwszą rzeczą, którą musimy wiedzieć, jest to, że wspólny numer starszy może być dostępny w obu węzłach klastra. Aby to zrobić, uruchom następujące polecenie na wszystkich węzłach wiązki, a wyświetli dostępny rdzeń liczb: Wybierz dla każdego węzła inny podstawowy procent dostępny w klastrze. Na potrzeby tego artykułu o umiejętnościach przyjmiemy, że głównym dostępnym numerem jest 57.Powerha. pojemność równoległa wymaga skonfigurowania dla nowej klasy woluminów (konfiguracja -C metoda komenda mkvg) des. Naprawdę trzeba też wyłączyć kworum -Qn) (używając i dodatkowo autozmienności, ponieważ jest unikatowe (używając opcji -i jako). PowerHA zmieni grupowanie woluminów dla naszej strony. Na koniec przydzielony numer zdecydowanie powinien być main podany (w przykładzie przy użyciu -V: 57 ). Aby obejść ten problem, uruchom ważne polecenie mkvg, rozwiń do grupy woluminów „Do” (Uwaga: zmień nazwę grupy woluminów, numer główny, a także nazwy dysków w zależności od sytuacji i preferencji): Uwaga: uruchom to faktyczne zarządzanie tylko na jednym z węzłów chaosu, a także na razie kontynuuj pracę nad węzłem grupy osób, aby określić kolejne kroki. Następnie utwórz inteligentny wolumen (skonfiguruj go zgodnie z własnymi preferencjami w ramach sytuacji głównej): Te instrukcje inicjują użycie woluminu logicznego fs01lv, użyj tej metody dla typu systemu plików jfs2 z sky 1 (wystarczy użyć 1 dysku) lub określ 1278 partycji na dysku hdisk38. manifestować system plików na kompletnym wcześniej zdefiniowanym woluminie logicznym: To polecenie tworzy również plik /fs01 dla woluminu logicznego fs01lv, używa dziennika w witrynie (zalecane ze względu na wydajność), nie rejestruje szczelin czasowych dostępu (options=noatime) w celu uniknięcia niepotrzebnej wiedzy o udziałach plików i nakazuje systemowi AIX zamontować plik ludzkiego ciała w systemie. uruchamianie (-A w kolejności nie), ponieważ PowerHA prawdopodobnie zamiast tego zamontuje system plików La. w przypadku korzystania z grupy woluminów, rozmiaru logicznego i utworzonego systemu rejestrowania. W zależności od sytuacji możesz zapisywać różne woluminy, grupy raportowania i inne logiczne kwoty. Następnie upewnij się, że widzisz, gęstości są różne, np. grupa pojemności fs01vg: Jeśli zakup varioff nie powiedzie się w tym ważnym momencie, sprawdź, czy varioff Jeśli nadal istnieją systemy, odmontuj systemy plików i uruchom kilka razy komendę Varoffvg danej osoby. Teraz “lspv”, uruchom oba węzły chaosu i spójrz na wymienione identyfikatory PVID. Wybierz dysk, na którym skonfigurowałeś siłę roboczą za pośrednictwem dysków pierwszego węzła, i weźmy przykład dysku dla pvid, 00fac78651b28b53. Na drugim węźle uruchom polecenie, aby oznaczyć grupę woluminów importvg (co spowoduje również wyświetlenie informacji o wszystkich woluminach logicznych i plikach obsługujących importowane systemy skonfigurowane w tej grupie woluminów), a nawet pobierz identyfikator PVID jednego z twardych, głównych numer zdefiniowany wcześniej. , w odniesieniu do tego przykładu: Czy masz dość powolnego działania komputera? Denerwują Cię frustrujące komunikaty o błędach? ASR Pro to rozwiązanie dla Ciebie! Nasze zalecane narzędzie szybko zdiagnozuje i naprawi problemy z systemem Windows, jednocześnie znacznie zwiększając wydajność systemu. Więc nie czekaj dłużej, pobierz ASR Pro już dziś! Powtórz fs01vg dla wszystkich dodatkowych zestawów na tych tomach w Twojej sytuacji. Upewnij się, że podczas dodawania tej grupy wagowej na drugim węźle możesz wybrać poprawny identyfikator PVID z jednego z typów dysków w grupie woluminów znajdującej się na pierwszym węźle, ponieważ absolutnie chcesz mieć pewność, że oba węzły wskazują na klaster PowerHA . te same nazwy grup dla poziomów głośności. W tym momencie wstrzymanie na obu węzłach jest starannie skonfigurowane i może nadszedł czas, aby dodać grupę zasobów powerha levelAnd. Najpierw sprawdź, którzy eksperci twierdzą, że chaos jest w dobrej formie, uruchamiając: Po potwierdzeniu zezwól PowerHA na wykrycie najbliższych dysków w klastrze: Teraz skorzystaj z grup woluminów w zestawie opcji klastra:
Zaktualizowano

Hacmp Group State Temporary Error
Tijdelijke Fout In Hacmp-groepsstatus
Erro Temporário De Estado Do Grupo Hacmp
HACMP 그룹 상태 일시적 오류
Hacmp Group State Temporary Error
Temporärer Fehler Im Hacmp-Gruppenstatus
Erreur Temporaire D’état Du Groupe Hacmp
Error Temporal Del Estado Del Grupo Hacmp
Временная ошибка состояния группы Hacmp
Errore Temporaneo Dello Stato Del Gruppo Hacmp